

Acing a global financial information company like Bloomberg's System Design interview
How to approach Bloomberg System Design interviews with real-world thinking, not just textbook architecture

If you approach the Bloomberg System Design interview expecting it to behave like a generic FAANG-style architecture discussion, you will likely miss the signal that the interview is actually trying to extract from you. Bloomberg does not operate in a domain where eventual consistency is casually acceptable or where latency spikes can be brushed aside as acceptable trade-offs for scale. It operates in a domain where financial data flows continuously, correctness is non-negotiable, and latency is not just a performance metric but a business constraint.
This changes how System Design is evaluated. You are not just being asked to design a scalable system; you are being asked to reason about systems that must remain correct under load, observable under failure, and predictable under stress. The difference sounds subtle at first, but it becomes obvious the moment you start discussing trade-offs.
A candidate who talks about horizontal scaling without discussing consistency guarantees will sound incomplete. A candidate who introduces asynchronous pipelines without addressing ordering or replay semantics will sound superficial. The interview is less about whether you know the components and more about whether you understand how those components behave when the system is no longer in a steady state.
The kind of systems Bloomberg cares about
To understand what Bloomberg is evaluating in their System Design interview, it helps to look at the types of systems they build internally. These are not social media feeds or generic e-commerce platforms. These are systems that deal with real-time financial data, trading workflows, analytics pipelines, and distributed data ingestion at scale.
The expectations from these systems are shaped by three persistent constraints: high-throughput data ingestion, low-latency query responses, and strong correctness guarantees even under partial failure.
The table below captures how Bloomberg-style systems differ from more typical large-scale systems that candidates often prepare for:
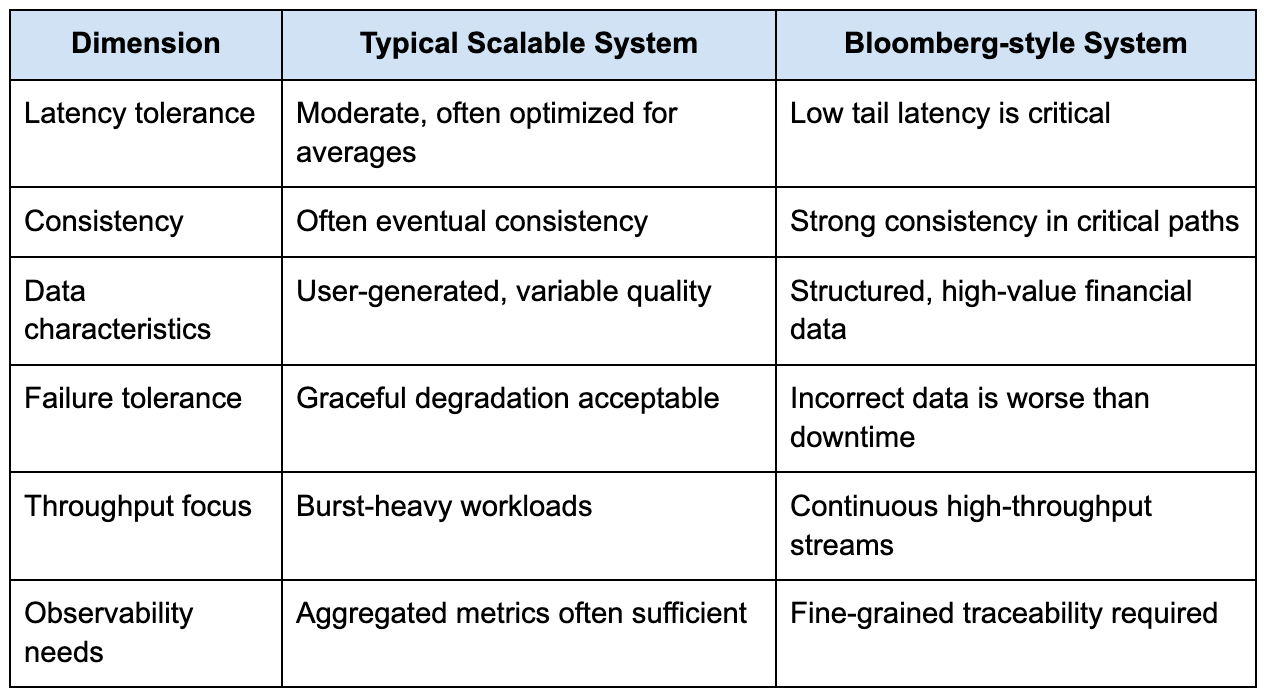
This difference fundamentally changes how you should approach the interview and understanding this can help you ace your System Design interview. If you treat the system as just another scalable architecture problem, you will likely over-index on components like load balancers and caches while under-explaining the correctness guarantees that Bloomberg systems actually depend on.
How Bloomberg frames System Design problems
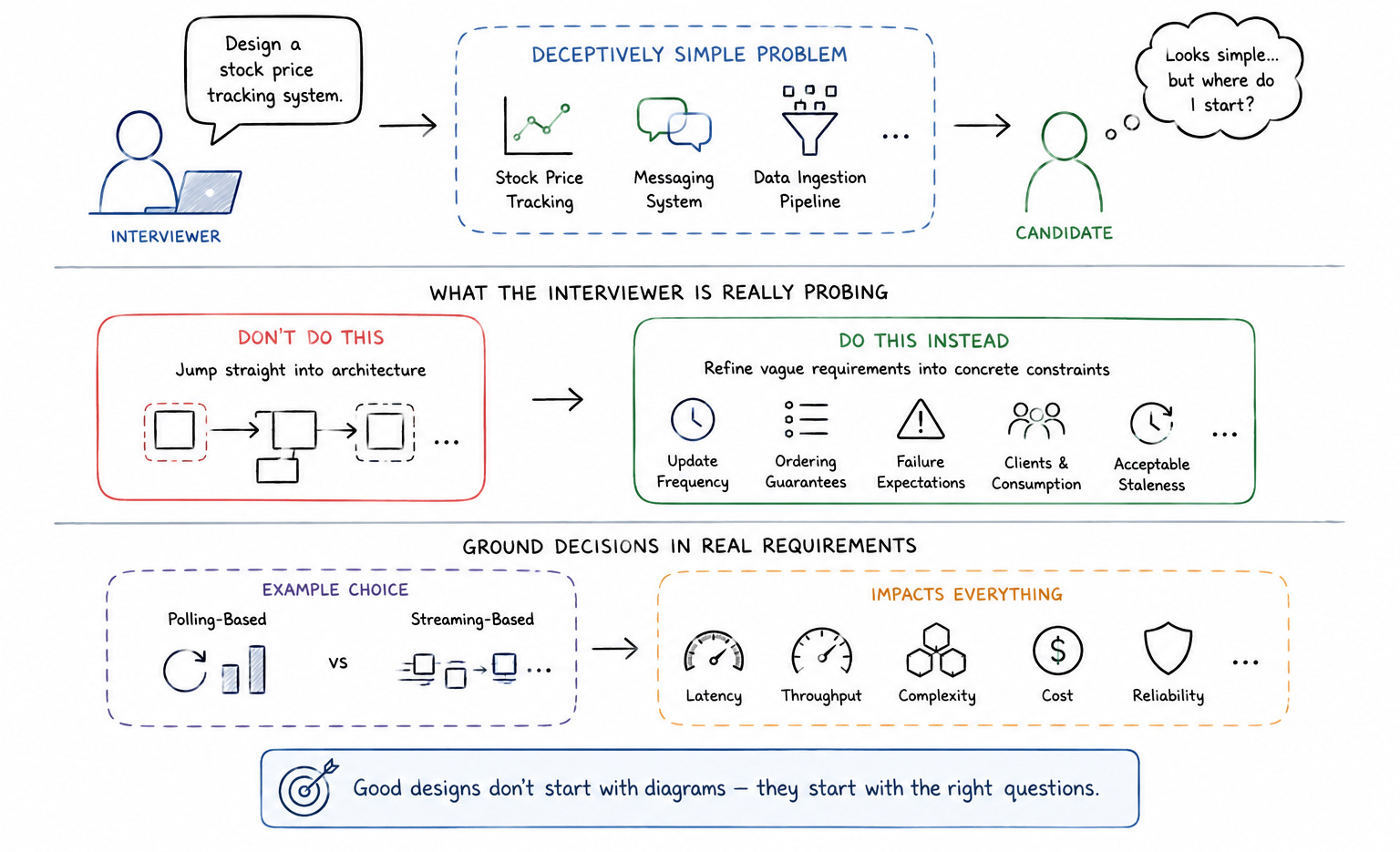
In most Bloomberg System Design interview questions, the problem itself appears deceptively straightforward. You might be asked to design a stock price tracking system, a messaging system, or a data ingestion pipeline. The surface-level requirements rarely look complex, but the depth emerges as the conversation progresses.
What the interviewer is really probing is how you refine vague requirements into concrete constraints. If you immediately jump into drawing a distributed architecture without clarifying update frequency, data ordering guarantees, or failure expectations, you are effectively designing in a vacuum.
n measurable realities. You want to understand how frequently data updates, what level of staleness is acceptable, how clients consume the data, and what happens when parts of the system fail. These questions are not just formalities; they define the shape of the architecture.
The difference between a polling-based system and a streaming system, for example, is not just an implementation detail. It directly affects latency, throughput, and system complexity. Without grounding that decision in requirements, the design becomes arbitrary.
A more grounded approach starts by anchoring the system i
A realistic example: designing a real-time market data system
Let’s walk through a representative System Design problem that aligns closely with Bloomberg’s domain. Suppose you are asked to design a system that ingests stock price updates and delivers them to clients in real time.
At a high level, the system has three core responsibilities. It needs to ingest data from multiple sources, process and normalize that data, and then deliver it to clients with minimal delay. The challenge is not in identifying these components, but in understanding how they behave under sustained load.
The table below outlines the core components and their responsibilities:
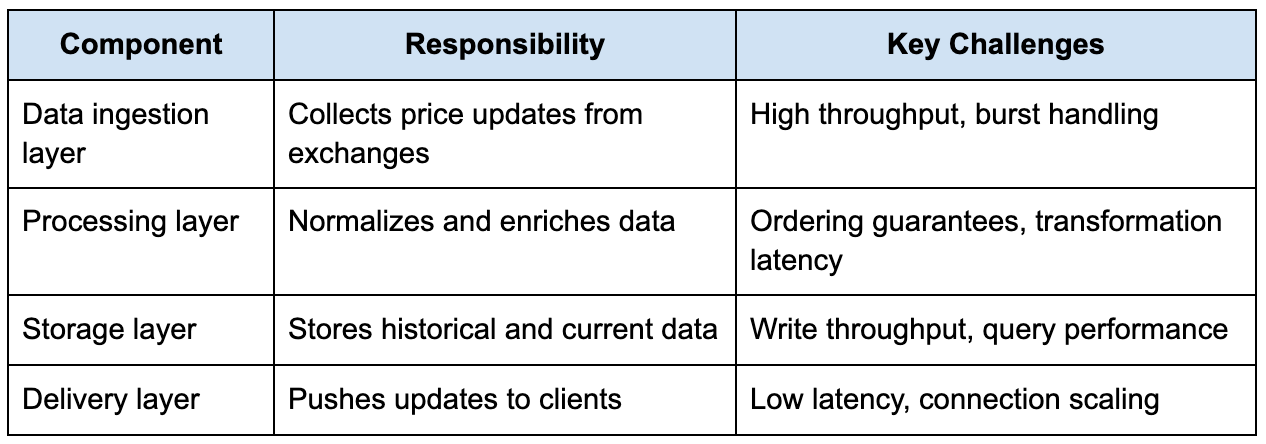
If you treat this as a simple pipeline, you might end up with a design that looks correct on paper but fails under real conditions. The moment you introduce real-world behavior, things become more complex.
For example, financial data often arrives out of order. If you process updates naively, you risk overwriting newer data with stale values. This means your system must incorporate ordering guarantees, either through timestamps, sequence numbers, or partitioning strategies.
Similarly, the delivery layer cannot rely solely on pull-based APIs if low latency is required. You need a push-based mechanism such as WebSockets or streaming protocols, but that introduces its own challenges around connection management and fault tolerance.
Where most candidates go wrong
One of the most common patterns I have seen in System Design interviews is the tendency to over-design early and under-explain trade-offs. Candidates often introduce message queues, distributed caches, and microservices without clearly explaining why those components are necessary at the current scale.
This is exactly the kind of premature architecture problem described in your reference text, where systems are designed for hypothetical scale rather than measured constraints.
In the context of a Bloomberg interview, this becomes even more problematic because unnecessary complexity makes it harder to reason about correctness. Every additional network boundary introduces latency, failure modes, and coordination overhead.
A more grounded approach is to start with a simple, well-structured system and evolve it based on constraints. If the ingestion rate is within the limits of a single node, there is no need to immediately distribute it. If latency requirements are not yet defined, introducing aggressive caching strategies may be premature.
The interview is not testing how many components you can name. It is testing whether you understand when those components become necessary.
Scaling decisions under real constraints
Once the system begins to experience real load, scaling decisions become unavoidable. The key is to tie those decisions to measurable signals rather than assumptions.
The table below illustrates how different scaling strategies align with specific bottlenecks:
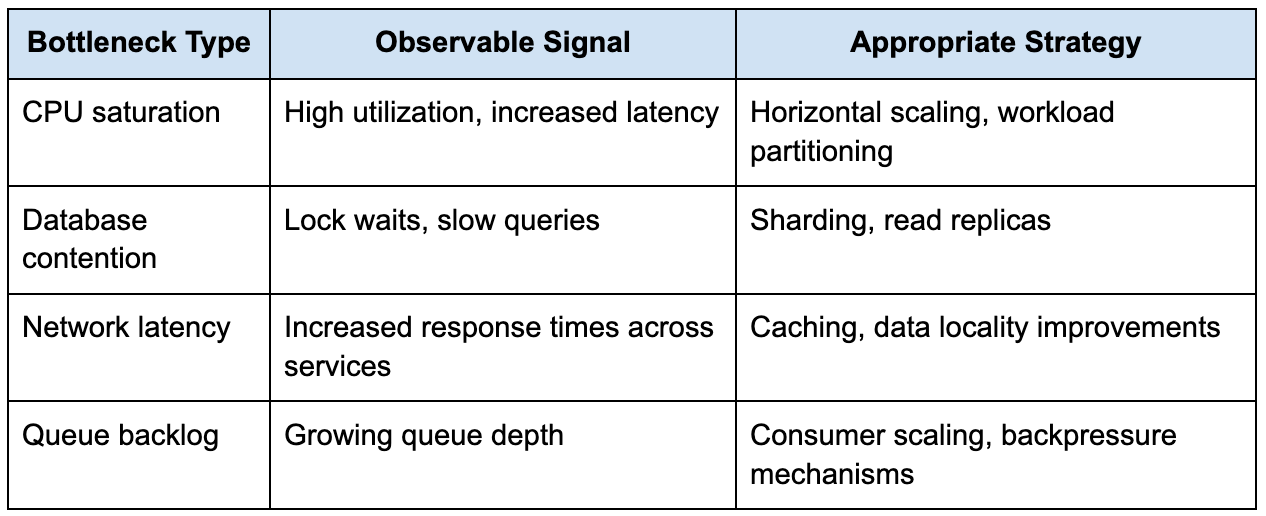
What stands out here is that each scaling decision is tied to a specific failure mode. This is exactly the kind of reasoning Bloomberg interviewers are looking for. They want to see that you are not just applying patterns, but diagnosing constraints.
For example, introducing a message queue without defining retry behavior or failure handling can create more problems than it solves. Under partial failure, retries can amplify load and lead to cascading failures, a pattern that is well-documented in real production systems.
Consistency and correctness in financial systems
One of the defining aspects of Bloomberg’s systems is the emphasis on correctness. In many consumer applications, eventual consistency is acceptable because minor inconsistencies do not significantly impact the user experience. In financial systems, incorrect data can have real-world consequences.
This means that consistency models must be chosen carefully. Strong consistency often comes at the cost of latency and availability, but in critical paths, that trade-off is justified. The challenge is to identify which parts of the system require strict guarantees and which can tolerate eventual consistency.
For instance, real-time price updates may need to be strongly consistent, while historical analytics can tolerate slight delays. Designing the system with this distinction in mind allows you to balance performance and correctness effectively.
Observability is not optional
One of the more subtle but critical aspects of Bloomberg-style systems is observability. When systems operate at high throughput and low latency, failures are often non-deterministic and difficult to reproduce.
Without proper instrumentation, debugging becomes guesswork. This is particularly important in distributed systems, where failures can propagate across multiple services.
A well-designed system includes structured logging, distributed tracing, and metrics that capture not just averages but tail behavior. P99 latency, for example, often reveals issues that are invisible in average metrics.
This aligns closely with the idea that you must understand your system’s performance envelope before attempting to scale it. Without that understanding, architectural decisions become speculative.
How to structure your answer in the interview
When you present your design, the structure of your explanation matters as much as the design itself. You want to start by grounding the system in clear requirements, then progressively introduce complexity as those requirements demand it.
Instead of jumping directly into a distributed architecture, begin with a simple model and explain its limitations. Then show how those limitations lead to specific design decisions. This approach demonstrates that you are not just applying patterns, but reasoning about constraints.
The progression should feel natural. Each new component should solve a clearly defined problem, and each trade-off should be acknowledged explicitly. This creates a narrative that is both technically sound and easy to follow.
What Bloomberg is really evaluating
At its core, the Bloomberg System Design interview is not about whether you can design the most scalable system. It is about whether you can design a system that behaves predictably under real-world conditions.
They are evaluating how you think about latency, consistency, and failure. They are looking for candidates who understand that scaling is not just about adding more machines, but about managing complexity and maintaining correctness.
The strongest candidates are not the ones who introduce the most components, but the ones who can justify every decision in terms of measurable constraints and real system behavior.
Final perspective
If there is one mindset shift that makes the biggest difference in this interview, it is moving away from designing for hypothetical scale and toward designing for observed constraints. Systems do not fail because they are too simple; they fail because complexity is introduced without a clear understanding of its cost.
The Bloomberg System Design interview reflects this reality. It rewards clarity over cleverness, reasoning over memorization, and depth over breadth. If you approach it with that mindset, your design will not just look correct on a whiteboard, it will feel grounded in the kind of engineering decisions that actually hold up in production.