

ChatGPT System Design: What really happens when you ask a question
Understanding how large language models are served at scale, from request orchestration to real-time token generation

If you approach ChatGPT System Design the same way you would approach designing a traditional backend service, the architecture quickly starts to feel either incomplete or misleading, because the system is about generating responses through computationally intensive inference that must happen in real time under strict latency constraints. The challenge is not just scale in terms of requests per second, but scale in terms of compute per request, which introduces a very different set of trade-offs compared to typical distributed systems.
What makes this system particularly interesting is that every user interaction triggers a sequence of operations that are both expensive and sequential, and that sequence must be orchestrated in a way that feels instantaneous to the user. Unlike a CRUD API, where responses are assembled from pre-existing data, here the response is generated token by token, and that generation process is tightly coupled with the underlying hardware and scheduling strategy.
If you do not start from that premise, it becomes easy to design abstractions that look clean on paper but fail to reflect the actual behavior of the system under load.
Understanding the request lifecycle
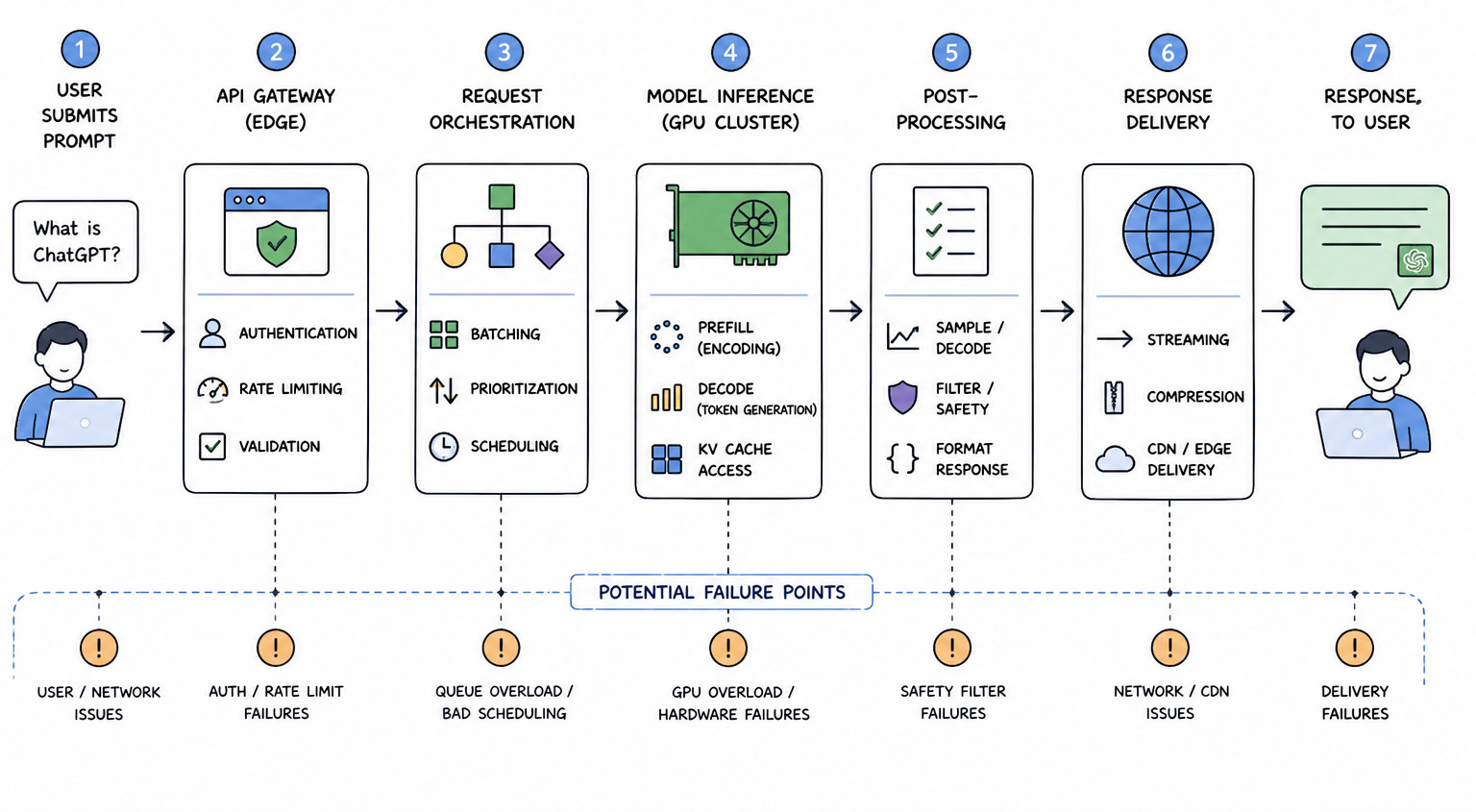
The most grounded way to reason about ChatGPT is to follow a single request from the moment a user submits a prompt to the moment a response appears on their screen, because that path exposes where latency is introduced, where compute is consumed, and where failures can occur. A user submits a prompt that may range from a simple question to a long multi-turn conversation, and the system must immediately determine how to process it, including how much compute it will require and how it should be scheduled relative to other requests.
At the edge of the system, the request is handled by an API gateway that performs authentication, rate limiting, and validation, and while this layer resembles what you would find in any large-scale system, its role is more critical here because it is protecting access to a scarce resource, which is GPU-backed inference. If too many requests are allowed through without control, downstream components can become saturated, leading to increased latency and potential cascading failures.
Once the request passes through the gateway, it is forwarded to a request orchestration layer that determines how the request will be processed. This layer is responsible for batching, prioritization, and scheduling, and it must balance two competing goals, which are maximizing hardware utilization and minimizing latency for individual users. Unlike traditional systems, where requests can be processed independently, here, batching can significantly improve efficiency, but waiting too long to batch requests can degrade user experience.
Core system components and responsibilities
To make sense of how the system operates, it helps to break it down into logical components, while keeping in mind that these boundaries are conceptual and may not always correspond to independent services in practice.
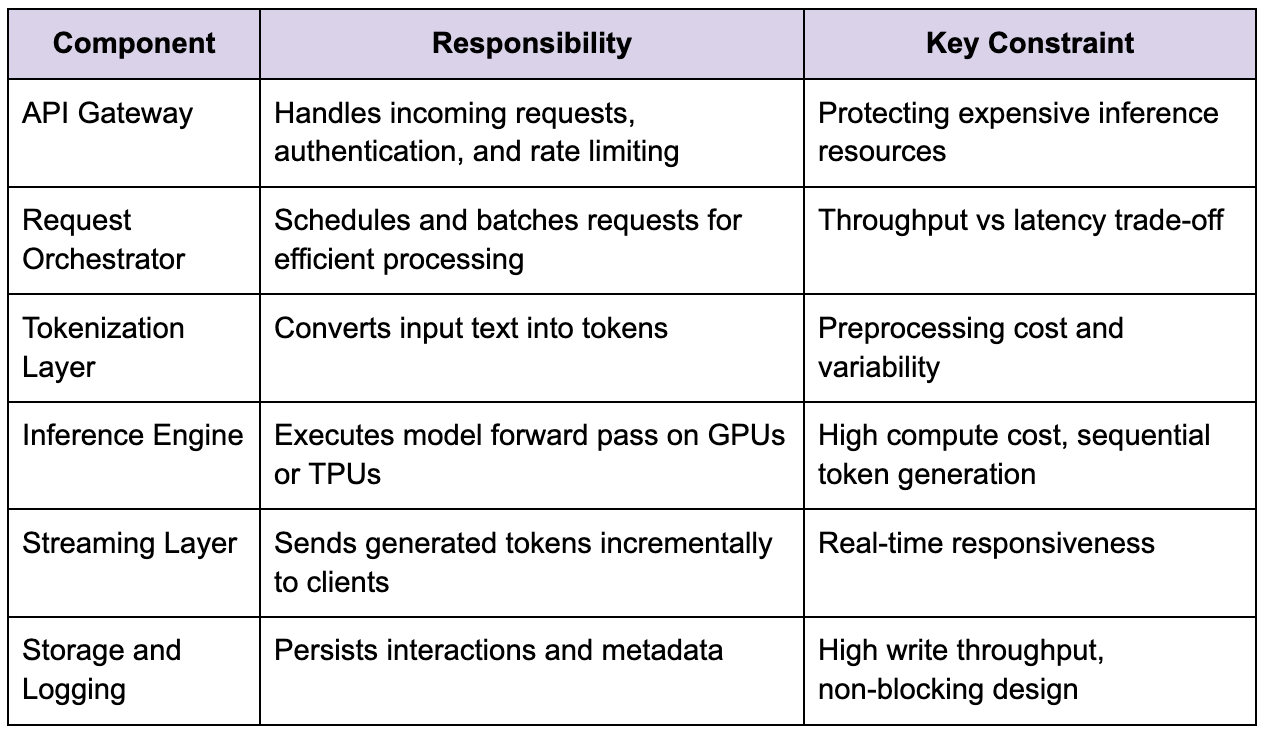
This separation helps in reasoning about the system, but it is important not to prematurely distribute these components without understanding actual load patterns, because introducing unnecessary boundaries adds coordination overhead and latency without delivering real benefits.
Tokenization and input variability
Before the model can process a request, the input text must be converted into tokens, and while this may appear to be a simple preprocessing step, it has a significant impact on system performance. The number of tokens determines the computational cost of inference, because transformer-based models scale with sequence length, particularly in attention operations where complexity increases rapidly as input grows.
This means that not all requests are equal, and the system must account for this variability when scheduling work. A short query might be processed quickly with minimal resource usage, while a long prompt with extensive context can consume significantly more compute and increase latency.
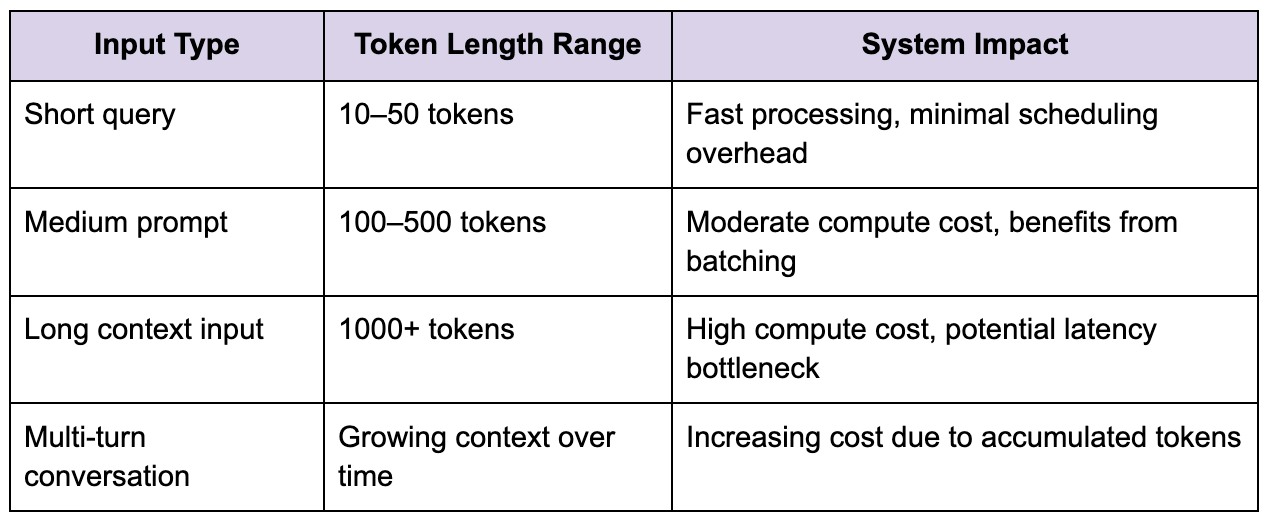
This variability introduces challenges in scheduling, because the system must ensure that large requests do not monopolize resources and degrade performance for others, while still providing acceptable latency for all users.
The inference engine and sequential computation
The inference engine is the core of the system, and it is where ChatGPT diverges most significantly from traditional backend architectures. Instead of executing deterministic business logic, the system performs a forward pass through a neural network with billions of parameters, and this process must be repeated for each generated token in the response.
One of the key constraints here is that token generation is inherently sequential, because each token depends on the previously generated tokens, which limits the amount of parallelism that can be exploited. While multiple requests can be processed in parallel, each individual request must progress step by step, which makes latency a critical concern.
This is why scaling ChatGPT is not simply a matter of adding more servers, because the bottleneck is not just the number of requests but the amount of compute required per request. Efficient utilization of GPUs or TPUs becomes essential, and this is where batching plays a crucial role, allowing multiple requests to share compute resources while maintaining acceptable latency.
Streaming responses and perceived latency
One of the design decisions that significantly improves user experience is the use of streaming responses, where tokens are sent to the client as they are generated rather than waiting for the entire response to be completed. This approach reduces perceived latency, making the system feel more responsive even though the total computation time remains the same.
Streaming introduces its own set of challenges, particularly in managing connections and handling backpressure. If the client cannot consume tokens as quickly as they are generated, the system must buffer or throttle output without disrupting the generation process. Additionally, maintaining persistent connections for streaming requires careful resource management, especially at scale.
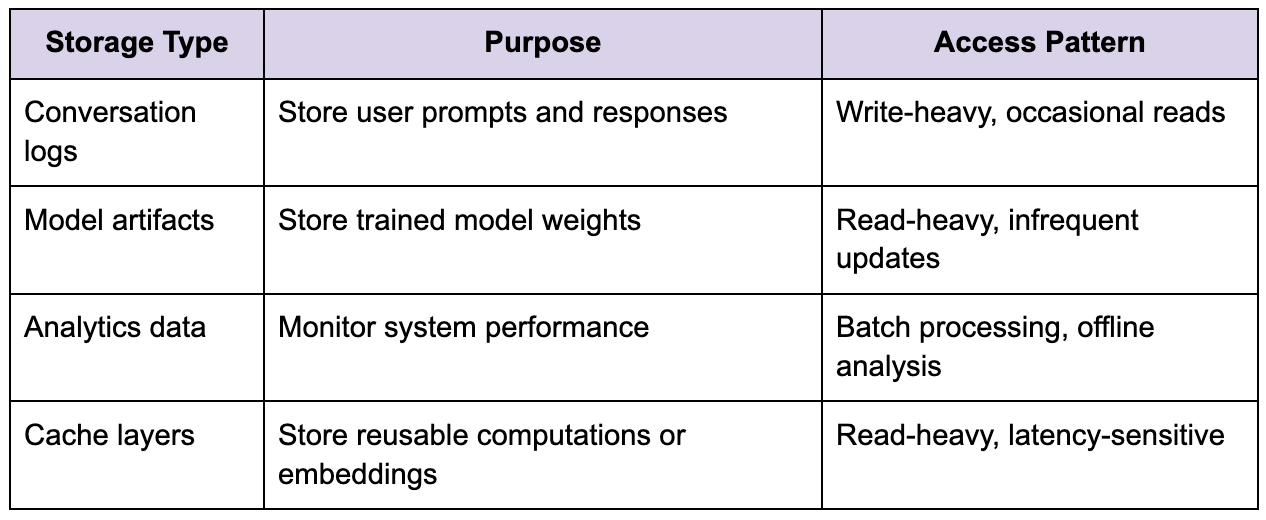
Storage and conversation management
Although ChatGPT does not rely on traditional databases for serving responses, storage still plays an important role in supporting features such as conversation history, analytics, and system monitoring. Conversation data must be stored in a way that allows efficient retrieval and integration into future requests, particularly for multi-turn interactions where context is essential.
Unlike systems where storage is part of the critical path for user interactions, here storage is often decoupled from the inference path to avoid adding latency. This allows the system to maintain responsiveness while still capturing valuable data for analysis and improvement.
Scheduling, batching, and resource allocation
One of the most complex aspects of ChatGPT System Design is scheduling, because the system must decide how to allocate limited compute resources across a highly variable workload. Batching is a key optimization, allowing multiple requests to be processed together to improve hardware utilization, but it introduces latency because the system must wait briefly to accumulate requests.
The challenge is to find the right balance, where batching improves efficiency without significantly increasing response time. This requires dynamic strategies that adapt to current load conditions, ensuring that the system remains both efficient and responsive.
Variability in request size further complicates scheduling, because large requests can dominate resources if not managed carefully. Techniques such as prioritization, token limits, and adaptive batching are used to mitigate this, but each comes with trade-offs that must be carefully considered.
Failure handling and system resilience
Failures in ChatGPT System Design are not just about returning errors, because partial responses may already have been streamed to the user, making recovery more complex. Additionally, the cost of reprocessing a request is high, so the system must minimize failures before they reach the inference stage.
One of the key risks is resource saturation, where GPU clusters become overloaded, leading to increased latency and request queuing. If not managed properly, this can create a feedback loop where delays cause retries, which in turn increase load and exacerbate the problem.
To prevent this, the system must implement mechanisms such as rate limiting, backpressure, and load shedding, ensuring that it remains stable even under high demand. Observability is critical here, providing the data needed to identify bottlenecks and respond to issues before they escalate.
Observability and performance monitoring
Understanding system behavior is essential for maintaining performance and reliability, particularly in a system as complex as ChatGPT. Metrics such as latency percentiles, request queue lengths, and resource utilization provide insight into how the system is performing and where bottlenecks may exist.
Tail latency is especially important because it reveals the outliers that can impact overall performance and user experience. Without detailed monitoring, it becomes difficult to predict how the system will behave under different load conditions or to identify the root causes of performance issues.
Tracing is equally important, allowing engineers to follow requests through the system and understand how different components interact. This is particularly valuable in diagnosing issues that span multiple layers of the architecture.
Evolving the architecture based on real constraints
One of the most important principles in designing ChatGPT is that the architecture should evolve based on observed constraints rather than hypothetical scenarios. Starting with a simpler design allows the system to adapt to real usage patterns, avoiding unnecessary complexity and ensuring that each component serves a clear purpose.
As demand grows, the system can introduce additional layers of distribution and optimization, extracting components that experience measurable pressure and scaling them independently. This incremental approach helps maintain system stability while allowing for continuous improvement.
Final perspective
ChatGPT System Design is about managing the interplay between compute-intensive inference and real-time user interaction in a way that feels seamless. Every design decision, from batching strategies to streaming responses, reflects a balance between efficiency and responsiveness.
What makes the system challenging is not the individual components but the way they interact under load, where small inefficiencies can compound into significant performance issues. Understanding these interactions is key to designing a system that not only scales but also delivers a consistent and reliable user experience.
In practice, the most effective design is one that prioritizes clarity and observability, allowing engineers to understand system behavior and make informed decisions. Without that understanding, it becomes easy to introduce complexity that does not align with real-world requirements, ultimately making the system harder to maintain and scale.