

Designing Instagram taught me why feeds are harder than databases
A practical guide to designing Instagram with feeds, media delivery, caching, and scale

Designing Instagram looks simple until you stop thinking about it as a photo app and start thinking about it as a global media distribution system with a social graph attached. A user uploads a photo, but behind that one action sits media processing, object storage, metadata indexing, feed generation, caching, CDN delivery, ranking, notifications, and abuse protection.
That is why “design Instagram” remains one of the most common System Design interview questions: it compresses almost every practical distributed systems problem into one familiar product. The strongest answers are not the ones with the most services on the diagram. They are the ones that explain where the system actually breaks under scale.
Recent System Design guides consistently frame Instagram around media storage, feed generation, caching, social graph scale, and real-time interactions.
Why Instagram is not just a CRUD app with images
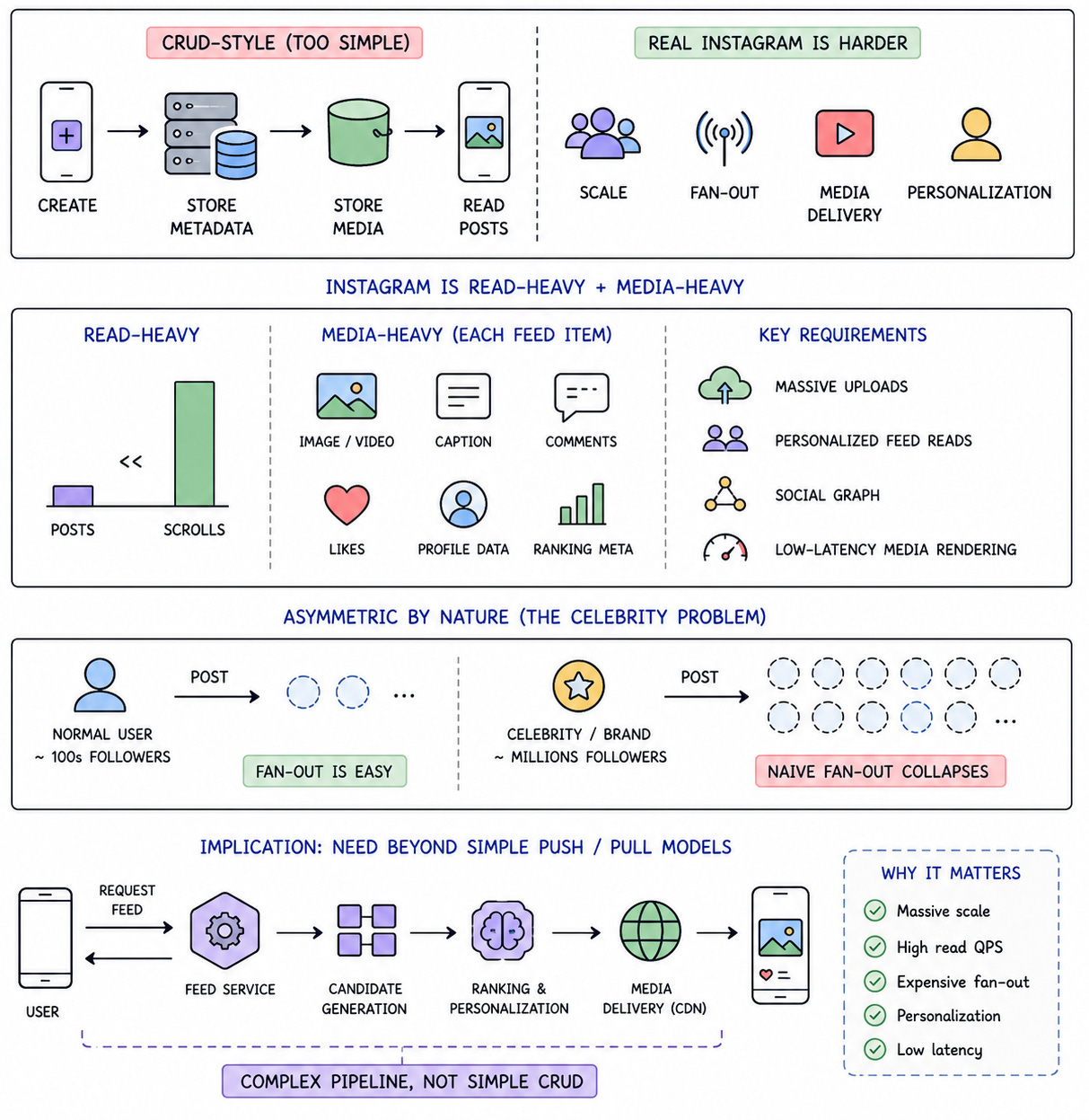
The first mistake candidates make is treating Instagram like a standard post-and-read application. If this were only about creating posts and fetching them later, the design would be straightforward. You would store user records, save post metadata in a database, upload images to object storage, and return posts through an API. That design works for a classroom version of Instagram, but it does not survive the real interview because Instagram’s hardest problems come from scale, fan-out, media delivery, and personalization.
A platform like Instagram is read-heavy because users scroll far more often than they post. It is also media-heavy because each feed item may include images, videos, captions, comments, likes, profile data, and ranking metadata. Modern walkthroughs of the Instagram design problem usually emphasize that the system must support massive photo and video uploads, personalized feed reads, social graph relationships, and low-latency media rendering.
The system is also asymmetric. A normal user may have a few hundred followers, while celebrities and brands may have millions. That one difference changes the entire feed architecture because a naive fan-out strategy works beautifully for normal users and collapses when a high-follower account posts. This “celebrity problem” appears repeatedly in Instagram feed design discussions because it forces you to move beyond simple push or pull models.
Clarifying requirements before drawing the architecture
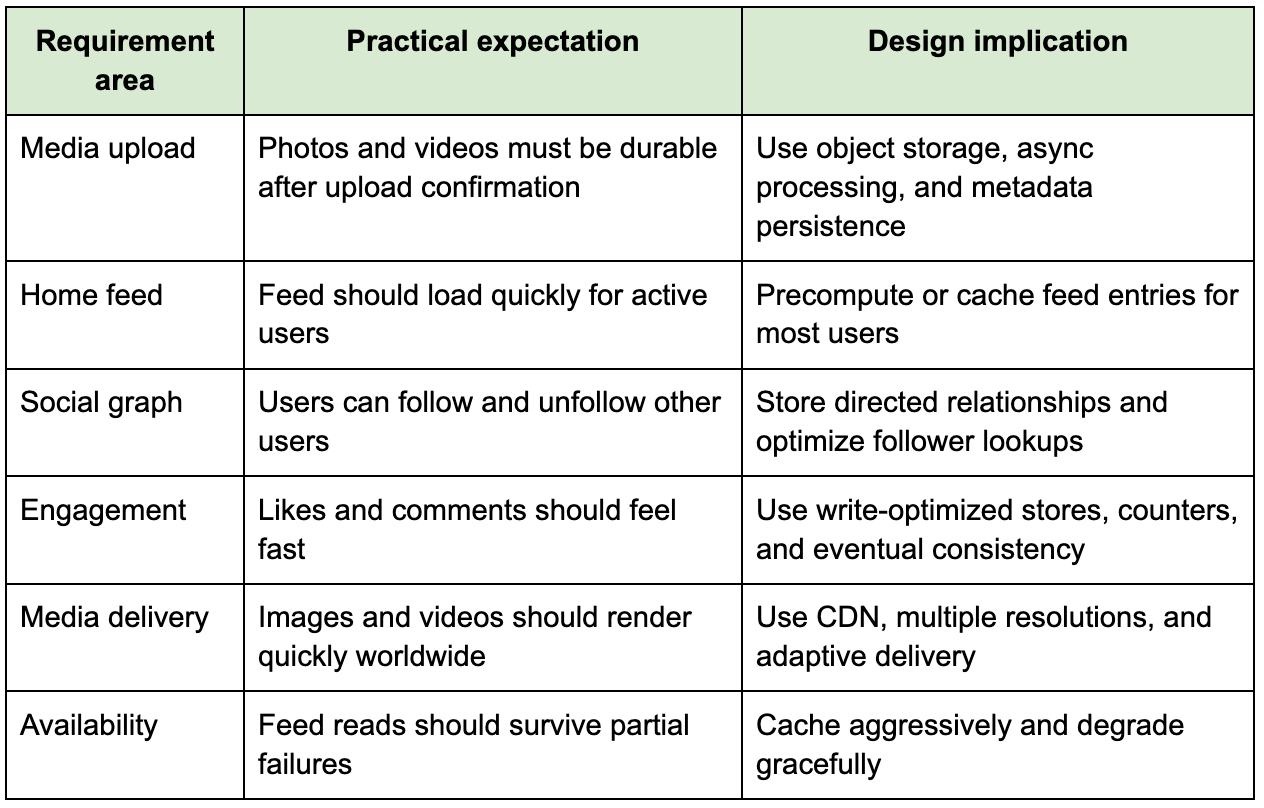
A strong interview answer starts by narrowing the scope. Instagram today includes posts, reels, stories, direct messages, live video, ads, shopping, recommendations, search, and creator analytics, but you cannot design all of that deeply in a 45-minute System Design interview. The practical scope is usually photo and video upload, user profiles, follow relationships, home feed generation, likes, comments, notifications, and media delivery.
The non-functional requirements matter more than the feature list because they determine architecture. The system should be highly available for reads, durable for uploaded media, low-latency for feed loading, horizontally scalable for user growth, and resilient during traffic spikes. Consistency requirements are mixed. A newly uploaded post should eventually appear in followers’ feeds, but likes and comments can tolerate slight delays. Uploaded media, however, must not be lost once the system confirms success.
This table is important because it keeps the design grounded. Without it, candidates often jump into microservices without explaining why the system needs each boundary.
The high-level architecture
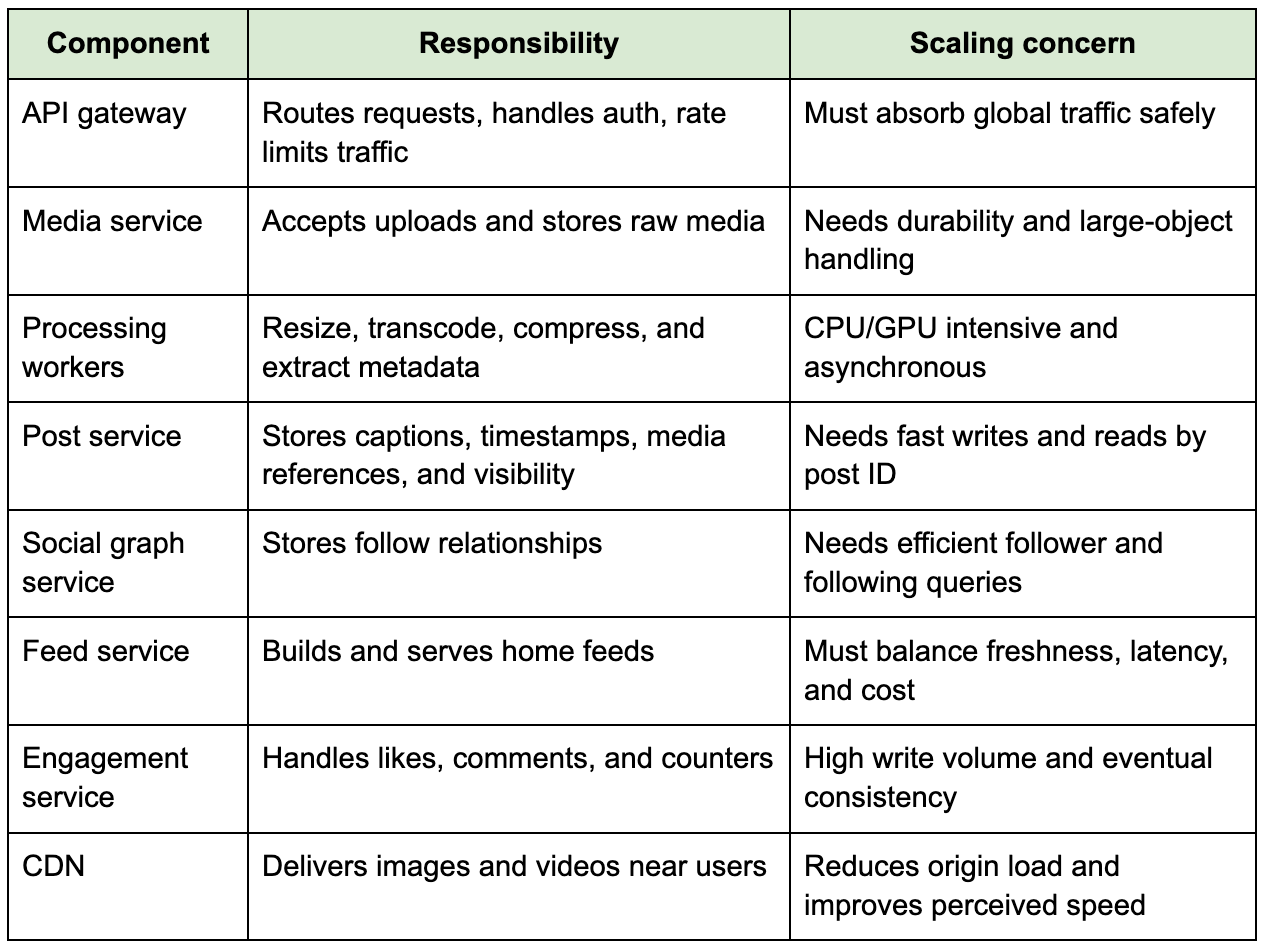
At a high level, Instagram needs clients, an API gateway, authentication, user services, media upload services, post metadata services, social graph storage, feed generation, caching, object storage, CDN delivery, engagement services, and notification pipelines. That sounds like many components, but each one exists because the workload behaves differently.
The upload path and read path should be separated early in the design. Uploads are write-heavy but less frequent than feed reads. Feed reads are extremely frequent, latency-sensitive, and cache-friendly. Media processing is expensive and should not block the user request longer than necessary. Notifications and feed fan-out are asynchronous because doing everything synchronously during upload would create unpredictable latency.
The architecture becomes much easier to reason about when you treat media as large immutable objects and metadata as queryable structured state. The image itself belongs in object storage and CDN. The post record belongs in a database. The feed contains references to posts, not the full media payload.
Designing the media upload pipeline
The media upload path should avoid routing large files through application servers when possible. A common approach is to let the client request a pre-signed upload URL, upload the file directly to object storage, and then notify the backend that the upload completed. This prevents application servers from becoming bandwidth bottlenecks.
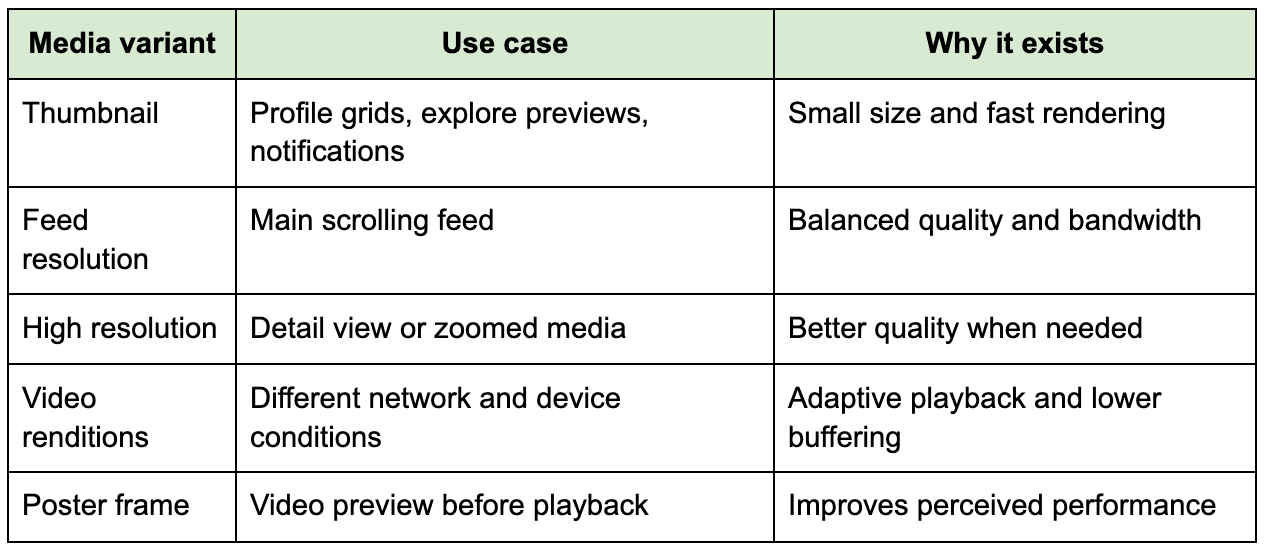
Once the original media lands in object storage, asynchronous workers generate multiple image sizes, video renditions, thumbnails, perceptual hashes, safety signals, and metadata. The system should not generate every possible transformation during feed reads because that would make scrolling depend on expensive compute. Preprocessing shifts cost away from the latency-sensitive path.
This is where candidates often under-design the system. They store the original image and assume the job is done. In production, the platform needs multiple variants because mobile networks, device screens, and feed contexts differ. A thumbnail for a grid view, a medium image for feed preview, and a high-resolution version for detail view should not all use the same asset.
The upload pipeline should also be idempotent. If the client retries after a timeout, the system should not create duplicate posts accidentally. This can be handled with upload session IDs, client-generated idempotency keys, and careful metadata state transitions.
Storing posts and media metadata
Instagram-like systems usually separate post metadata from media binaries. A post record may include post ID, author ID, caption, media object references, creation timestamp, visibility status, moderation status, and counters. The database should support fast reads by post ID and author ID, because profiles need to display a user’s posts efficiently.
A relational database can work at a smaller scale, but at the Instagram scale, the metadata layer often requires sharding. The natural shard key is usually the user ID or the post ID, depending on access patterns. Sharding by user ID makes profile retrieval efficient because a user’s posts live near each other. Sharding by post ID distributes write load more evenly, but may make profile queries more scattered unless secondary indexes or denormalized views are maintained.
The practical interview answer is to acknowledge both options. If profile access is a major use case, storing user post timelines separately can improve reads. If global write distribution matters more, post ID sharding with an author-post index may be preferable. The key is not picking a database name immediately. The key is explaining what access pattern drives the storage layout.
The social graph is simple until celebrities appear
Follow relationships form a directed graph. If Alice follows Bob, Alice’s home feed should include Bob’s posts, but Bob does not automatically follow Alice. The system needs efficient queries for “who does this user follow?” and “who follows this user?” because feed generation and fan-out depend on both directions.
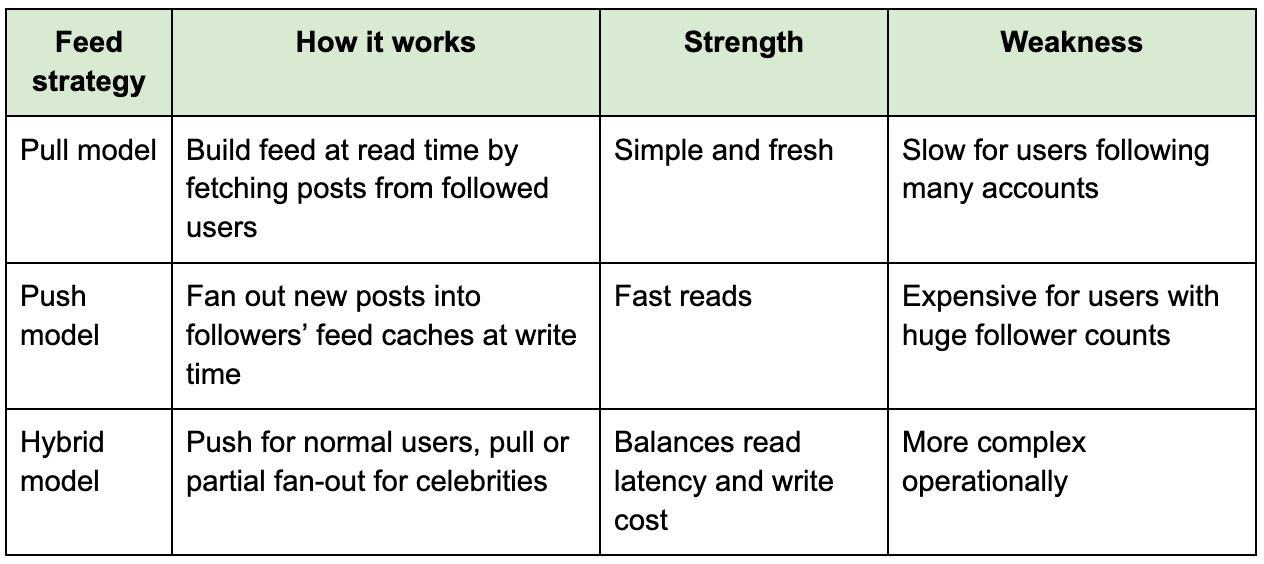
For normal users, follower lists are manageable. For celebrities, follower lists become enormous. If a celebrity with 100 million followers posts, pushing that post synchronously into every follower’s feed would overload the system. This is why Instagram-like systems usually use a hybrid feed model rather than a pure push or pure pull design.
The hybrid model is usually the best interview answer. For regular accounts, fan out posts to follower feed caches asynchronously. For celebrity accounts, avoid pushing to all followers immediately and instead merge their recent posts during feed read or distribute gradually through a separate high-fanout pipeline.
Feed generation is the core of the interview
The home feed is the hardest part of the classic Instagram design problem because it sits at the intersection of social graph scale, ranking, caching, freshness, and latency. A naive design fetches all followed users, queries their recent posts, sorts by time, and returns the latest items. That works for small systems, but it becomes expensive when users follow hundreds or thousands of accounts.
A better design precomputes feed entries for active users. When someone posts, a fan-out service reads their follower list and writes the new post ID into each follower’s feed cache or feed table. When a follower opens the app, the feed service reads a precomputed list of post IDs, hydrates metadata, fetches engagement counters, and returns media URLs pointing to CDN assets.
This design makes reading fast, which matters because feed reads dominate traffic. However, it moves complexity to the write path. Fan-out workers must handle backpressure, retries, duplicate delivery, queue failures, and celebrity accounts. That tradeoff is exactly what interviewers want to hear.
The feed should store references, not full posts. A feed entry may contain user ID, post ID, author ID, creation time, ranking score, and lightweight visibility metadata. The service can then hydrate full post details from caches and databases. This avoids duplicating heavy post records across millions of feeds.
Ranking versus chronological order
Many interview versions begin with a chronological feed because it is easier to design and explain. However, real Instagram feeds are ranked, not purely chronological. Ranking introduces another layer of complexity because the system now needs features, models, engagement predictions, freshness signals, and diversity logic.
In an interview, you can start with chronological ordering and then extend to ranking. That progression is natural because it shows you can build the simple system first and evolve it. A ranked feed might combine posts from followed users, recommended posts, ads, reels, and stories, then score them based on relationship strength, recency, engagement probability, content type, and user behavior.
The important production insight is that ranking should not make feed reads slow. Expensive ranking features can be precomputed offline or cached. Online ranking should be lightweight enough to meet latency goals. If every feed request triggers heavy model inference across thousands of candidates, the system will become expensive and unpredictable.
Caching strategy for Instagram
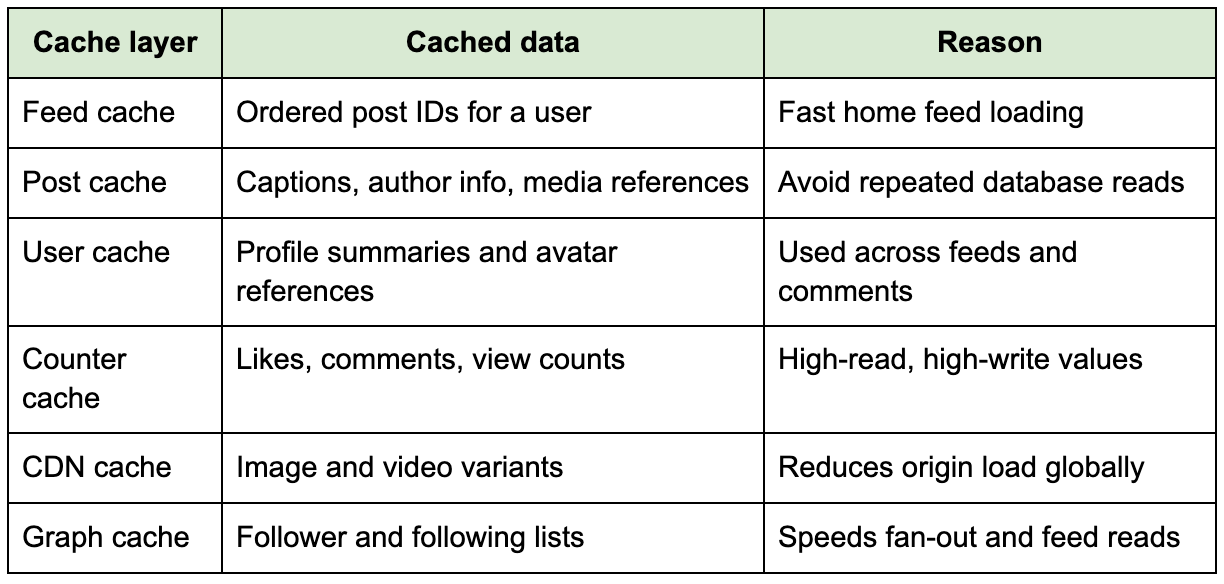
Caching is not optional in Instagram. The system needs cache layers for sessions, user profiles, post metadata, feed entries, follower lists, engagement counters, and media delivery. Without caching, repeated feed hydration would overload databases quickly.
The most important cache is the home feed cache. Active users can have their feed precomputed and stored in Redis-like systems or specialized feed stores. Post metadata can also be cached because the same post may appear in many feeds. Engagement counters are good cache candidates, but writes must be handled carefully because likes and comments generate high-frequency updates.
The cache invalidation strategy should be selective. If a user edits a caption, the post metadata cache should update. If a post is deleted or made private, feed entries referencing it may remain temporarily but should be filtered during hydration. That kind of defensive filtering is important because fully removing a post from every cached feed immediately may be expensive.
Likes, comments, and counters
Engagement features look easy until they receive massive write traffic. Likes should feel instant, but the exact like count does not need strict immediate consistency. A common design is to write the like event to a durable store or event stream, update a cache optimistically, and aggregate counters asynchronously.
Comments require stronger ordering than likes because users expect conversation order to make sense. The comment service should store comments by post ID and timestamp, with pagination support. Hot posts may need special handling because a viral post can receive massive comment and like traffic in a short period.
Counters are often eventually consistent. The displayed like count may lag by a few seconds during spikes, which is acceptable for most social products. What is not acceptable is losing engagement events permanently. This distinction lets the system optimize user experience without pretending every counter update requires a distributed transaction.
Stories and ephemeral content
If the interview includes stories, the architecture changes slightly because stories are time-bound and usually expire after 24 hours. That makes them different from permanent posts. The system can store story metadata with expiration timestamps and use TTL-based storage or scheduled cleanup workers.
Stories are also read frequently from close social connections, so they benefit from separate caching and ranking logic. The feed may prioritize recent stories from users with strong relationship signals. Media delivery remains similar to posts, but expiration and ordering become central.
The important thing is not to let stories derail the main design. In an interview, stories can be presented as an extension that reuses the media pipeline while adding expiration, separate ranking, and lightweight viewer tracking.
Notifications and asynchronous pipelines
Notifications should not be sent synchronously during every post, like, or comment request. If a user comments on a post, the comment write should succeed independently of notification delivery. A notification event can be published to a queue, processed by workers, deduplicated, rate-limited, and delivered through push notification providers.
This asynchronous design protects the core user action from downstream failures. If push notifications are delayed, users may be annoyed. If comment creation fails because a notification provider is slow, the product feels broken. That separation is one of the clearest signs of a mature System Design answer.
The same principle applies to analytics, ranking updates, moderation, and recommendation features. They should consume events from the core system rather than blocking the main request path.
Availability and graceful degradation
Instagram should degrade gracefully when dependencies fail. If ranking is unavailable, the feed can fall back to chronological cached entries. If engagement counters are stale, posts can still render. If comments are delayed, feed scrolling should remain functional. If media processing is behind, the app can show placeholders until processed variants become available.
This matters because a platform like Instagram has many subsystems, and not every subsystem deserves to take the whole product down. The feed read path should be protected especially carefully because it is the most visible user experience. Caches, CDNs, and fallback feed strategies help keep the product usable during partial outages.
The upload path has different priorities. Once the system acknowledges an upload, the media must be durable. If processing workers are delayed, that is acceptable. If raw media is lost after success, that is a serious correctness failure.
Observability for an Instagram-like system
Observability needs to cover more than CPU and memory. The system should track feed generation latency, cache hit rates, fan-out queue depth, media processing lag, CDN hit ratio, upload failures, post hydration latency, engagement write throughput, notification delay, and database shard health.
The celebrity problem also needs specific monitoring. When a high-follower account posts, fan-out systems should detect the workload and route it through special handling rather than allowing queues to explode. Queue depth, consumer lag, retry rates, and dead-letter counts become critical signals.
A good interview answer includes these signals because it shows you are designing a production system, not just a diagram. Instagram-like platforms fail gradually before they fail visibly. Feeds become stale, media takes longer to process, counters lag, and notifications arrive late. Without observability, those failures look like random user complaints.
How I would present the final design in an interview
I would start with a scoped version of Instagram that supports media upload, profiles, follows, home feed, likes, comments, and notifications. I would store media in object storage, deliver it through a CDN, and process variants asynchronously. I would store post metadata separately from media and shard it based on access patterns.
For feed generation, I would use a hybrid model. Normal users get write-time fan-out into feed caches because that makes reads fast. Celebrity users avoid full immediate fan-out, and their posts are merged into feeds during read time or distributed through controlled asynchronous pipelines. This handles the most important scaling problem without pretending one strategy works for every account.
For caching, I would cache feed entries, post metadata, user summaries, follower lists, counters, and CDN media aggressively. For engagement, I would use event-driven writes and asynchronous counter aggregation. For reliability, I would design graceful fallbacks so that stale counters or delayed notifications do not break feed consumption.
Final thoughts
Designing Instagram is difficult because it looks familiar. Everyone understands the product, so candidates underestimate the system. The real challenge is not uploading a photo or storing a caption. The real challenge is delivering personalized media feeds quickly and reliably while handling uneven social graph distribution, enormous read traffic, celebrity fan-out, global CDN delivery, engagement spikes, and partial failures.
The best design is not the one with the most fashionable infrastructure. It is the one that separates media from metadata, separates upload from processing, separates feed reads from fan-out writes, and separates core user actions from asynchronous side effects. That structure keeps the system understandable as it scales.
And that is the lesson behind the Instagram System Design interview. You are not being tested on whether you can name object storage, Redis, Kafka, and a CDN. You are being tested on whether you understand why each of those pieces exists, where each one fails, and how to keep the user experience fast when the platform is under pressure.