

Designing Stripe for Black Friday: how to achieve 99.9999% uptime
A lesson on scaling for spikes through capacity planning and load testing.

Last week, we examined how Ticketmaster handled the ticket sales for Taylor Swift's upcoming tour. The enormous demand from her fans – and bots – caused a traffic spike that superficially resembled a DDoS attack. (If you missed my Ticketmaster newsletter, you can find it here).
This week, we'll look at how companies like Stripe successfully avoided downtime from traffic spikes on two of the biggest eCommerce days of the year: Black Friday and Cyber Monday (BFCM). We'll dive into how these companies build their payment services by emphasizing scalability and planning for system longevity.
I want to talk about Stripe in particular today because of a recent tweet from Stripe CTO, David Singleton (@dps), who claimed that Stripe had achieved uptimes of greater than 99.9999% for some of the busiest days of the year for eCommerce.


This is equivalent to an approximate downtime of 30 seconds per year, which is an incredible feat to achieve, even if it's just for one weekend.
The fact that Stripe can achieve such high availability times is a testament to the expertise of its engineering team. It's also a testament to the importance of robust modeling and testing regarding capacity planning, which I will unpack here.
Educative is offering a year-end discount — get 10-20% off Educative Premium, which includes all of our System Design, interview prep, API, cloud, and tech skills content.
Stripe's workload and capacity planning
Engineering for peak performance through modeling and testing is especially important during the peak shopping season when eCommerce sites are expected to handle hundreds or even thousands of transactions per second.
To safeguard against system failure, companies like Stripe extensively test their systems by ramping up traffic to simulate Black Friday or Cyber Monday scenarios, and by load-testing the entire infrastructure from top to bottom.
When you're operating on the same scale as Stripe, just a few minutes of downtime can be incredibly costly. Singleton pointed out that even a mere 5 minutes of downtime could account for astronomical revenue losses — in the tens of millions!
During BFCM, Stripe was experiencing peak loads of more than 20,000 requests per second while handling over $3B transactions daily. That's almost $333K per second, so you can see why it's easy for them to justify the costs of robust capacity planning.
Their approach to testing appeals to me because they're not just being proactive about preventing disasters. They're also exemplifying a growth mindset because being able to reliably forecast the demand on their platform is essential for long-term success as a company.
In his Twitter thread, Singleton mentioned that the volume of traffic Stripe experiences on BFCM quickly becomes their daily traffic. So, BFCM represents an opportunity for them to optimize their infrastructure for when their peak load becomes their average load.
The ability to plan for peak loads, understand your infrastructure’s limits, and simulate similar scenarios helps ensure that no matter how high the demand gets, the system can remain stable and secure.
How will your system change? How will it be maintained? How will it scale to meet the needs of a growing customer base? These are all questions that you should ask no matter what scale you're operating at.
Good systems engineers always consider the future of their services and technologies, and Stripe is an excellent example of how great systems don't just invest in capacity planning to survive.
They use it to thrive.
Understanding availability for building software systems
Before we get into the weeds talking about the specifics of Stripe's payment platform, I'd like to touch on the importance of understanding availability.
Availability is the percentage of uptime in a given time frame.
Service level agreements (SLAs) are how systems engineers communicate the expected availability of systems. The higher the uptime percentage, the better.
For most SLAs, three or four nines are typical. This translates to around one hour to eight hours of downtime per year. AWS, for example, promises SLAs of three nines.
However, Stripe basically experienced zero downtime for BFCM with six nines, which is incredibly ambitious for an SLA. Stripe has a 90-day average uptime of five nines, which is also pretty impressive.
Understanding availability is useful for any engineer, so here are some back-of-the-envelope calculations you can practice with.
Availability is the quotient of uptime over the sum of uptime and downtime.
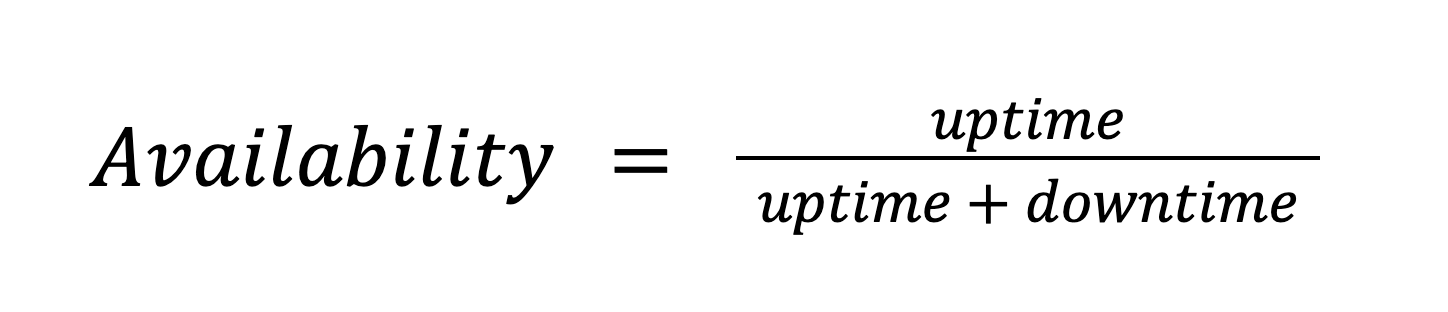
You can use an uptime calculator or availability table like the one below to translate this percentage to time.

If you don't have an availability table handy, a quick way to calculate the seconds/day of downtime would be to use the "Powers of 10" trick:

So, if a system has availability of 99.999% (or five nines), then n = 5.
When interviewing, you may be asked to calculate the availability for a given system or answer questions about how to increase availability. Having these equations memorized is a quick and near-effortless way to guarantee that you'll always be prepared to answer these questions.
Now, let's get back to Stripe.
An overview of Stripe's payment gateway
A payment gateway is a service for authorizing and processing credit card payments or direct payments for e-commerce or brick-and-mortar businesses. Transactions are facilitated by transferring information between a payment portal and the acquiring bank.
On the surface, payment gateways are fairly simple. The main need for services like Stripe is the heavy regulations on credit card transactions as stated in the Payment Card Industry (PCI) data security standards.
Stripe, and other payment gateway platforms, exist as a way for 3rd party sellers to comply with PCI standards while selling their products online.
Stripe tracks and processes payments with a PaymentIntents object. This object represents the merchant's intent to collect payment from a customer. The object's state will change over the course of the process depending on what step the system is on.
This is all monitored/controlled by the PaymentIntents API. If you're interested in learning more about the Stripe API, check out our Integration with Stripe API course.
Below, is a diagram that I created to show how this API works within a larger payment gateway system.

How does Stripe’s payment gateway work?
I'll briefly walk you through the basic workflow that Stripe's payment gateway goes through for an average online card transaction. (Please refer to the above figure.)
A user navigates to a payment page. This can be generated by the merchant site or by Stripe.
The system sends order information to the server, and Stripe returns a new PaymentIntent object for monitoring the transaction.
The user enters their credit card information to the payment page.
Creates a unique key called "client_secret" for abstracting sensitive metadata information from the transaction. This key is contained in the PaymentIntent object.
Stripe then attempts a payment redirect to the user's card network (and ultimately the issuing bank).
The bank checks for funds and either accepts or rejects the payment request.
If successful, the transfer is initiated with the acquiring bank
A webhook with the payment status is sent to the server.
The payment status is displayed for the user.
Modeling system longevity
Given that the above process is just for online credit card transactions, Stripe is a very intricate system. The real star of the show on Black Friday and Cyber Monday was the PaymentIntents API, with a 99.9999% API call success rate. This extremely high level of accuracy for the API was integral in keeping the system as responsive and error-free as possible.
The engineers at Stripe were able to reach this level of accuracy through intense stress testing. There is no other way to ensure the success of a system other than testing and modeling. If you haven't stress-tested a system at its peak load, if you haven't explored those limits, there may be a host of unseen problems waiting to jump out.
It's always better to over-prepare than be caught off guard by something. To illustrate this point, there is a historical anecdote we love to tell in the System Design world about the Golden Gate Bridge.
In the 1930s when engineers were designing and building the bridge, they didn't have perfect models for how the environment would affect the bridge. Trying to take into account the wind, waves, and the salty spray of the San Francisco Bay was a challenge. They couldn't nail down a perfect figure that ensured the bridge would hold and last, while staying budget-friendly. So, the architects decided to just multiply everything by six.
Now, with modern technology, we can reassess the bridge's load and the environmental stressors to determine that they only needed to 3x everything, but it was much better to be on the safe side.
Test, test, and test some more
I hope you enjoyed this third part in this series on scalable systems in-practice! (If you want to catch up on recent newsletters, including my issues on Twitter and Ticketmaster System Design, I have also published them to my Substack). The main takeaway from this Stripe success story is that there is no replacement for stress testing.
Another quick anecdote: early on when my team at Microsoft was building Azure, some edge cases would crop up and crash the system. Writing the code to recover was so complex that we would just deny the request and start again. As the system scaled, however, this problem that started out happening maybe once a month became more frequent: once per week, once per day, etc.
As a system scales, uncommon errors become more and more frequent. If left unchecked, they could go from happening every few weeks to hundreds or even thousands of times a day.
In his Twitter thread, the CTO of Stripe mentioned that they identified and resolved 25 issues and anomalies. Because of this diligence, they didn't experience anything unprecedented on Black Friday or Cyber Monday.
This was important not just for Stripe, but for the millions of users around the world who depend on Stripe for payment processing. The e-commerce load is so immense on Black Friday and Cyber Monday that the global economy would feel a hit were a system like Stripe to go down. (This is also true for other players in this space, like PayPal and Paddle, who work to ensure that customers have a seamless – and fast – checkout experience).
If you're interested in Stripe beyond just a casual look under the hood, check out this Stripe Coding Interview guide from codinginterview.com. You can find the playbook for how to approach the Stripe interview process, with tips and best practices from Stripe interviewees.
One more reminder: Educative's end-of-year sale is happening right now. There has never been a better time than right now to start learning System Design, and with Educative Premium, you will get access to our new System Design course: Grokking Modern System Design Interview for Engineers and Managers, plus hundreds of others! You can even create Personalized Paths, a tailored curriculum to help you reach your unique learning goals.
Give it a try, and let me know what you think.
Happy learning!