

Grokking System Design interview changed how engineers approach scale
Why experienced engineers still struggle with System Design interviews and how structured systems thinking changes the conversation

When I first started interviewing engineers for senior backend and distributed systems roles, I noticed something interesting. Many candidates understood databases, APIs, caching, and networking independently, but they struggled when asked to connect those pieces into a scalable production system under real-world constraints.
The problem usually was not intelligence or experience. It was structured. System Design interviews force engineers to reason about ambiguity, scale, tradeoffs, and operational behavior simultaneously, which is very different from solving isolated coding problems. That gap is one of the main reasons Grokking the System Design Interview resonated with so many engineers over the years, especially developers transitioning from implementation-focused roles into architectural thinking.
Why System Design interviews have become difficult for experienced engineers
One of the misconceptions people have about System Design interview questions is that years of engineering experience automatically translate into strong interview performance. In reality, many highly capable engineers struggle in these interviews because day-to-day development work rarely requires explaining architecture decisions from first principles in a structured way.
A backend engineer may spend years building APIs, optimizing queries, and maintaining production services successfully, but System Design interviews introduce a different kind of pressure. Suddenly, the engineer must reason about throughput, latency, reliability, scaling limits, partitioning strategies, replication behavior, infrastructure failures, and operational tradeoffs in real time while communicating clearly.
That combination creates friction even for strong engineers because scalable systems are not built around isolated technical concepts. They are built around interactions between components under unpredictable workloads.
The shift from coding problems to systems thinking
Coding interviews reward precision. System Design interviews reward judgment.
That distinction matters because there is rarely a single correct architecture for large-scale systems. Instead, engineers are evaluated on how they approach uncertainty, how they prioritize constraints, and how they justify tradeoffs.
For example, a candidate designing a messaging platform may choose aggressive caching to reduce latency, but then the discussion shifts toward cache invalidation and consistency. Another candidate may prioritize strong consistency through synchronous writes, but the interviewer may then explore throughput limitations and latency spikes under scale.
The conversation evolves continuously because large systems are defined by competing priorities.
This is one of the biggest reasons structured frameworks became important in System Design preparation. Engineers needed a way to organize architectural reasoning instead of approaching every interview as a random brainstorming session.
Why structured thinking matters more than memorization
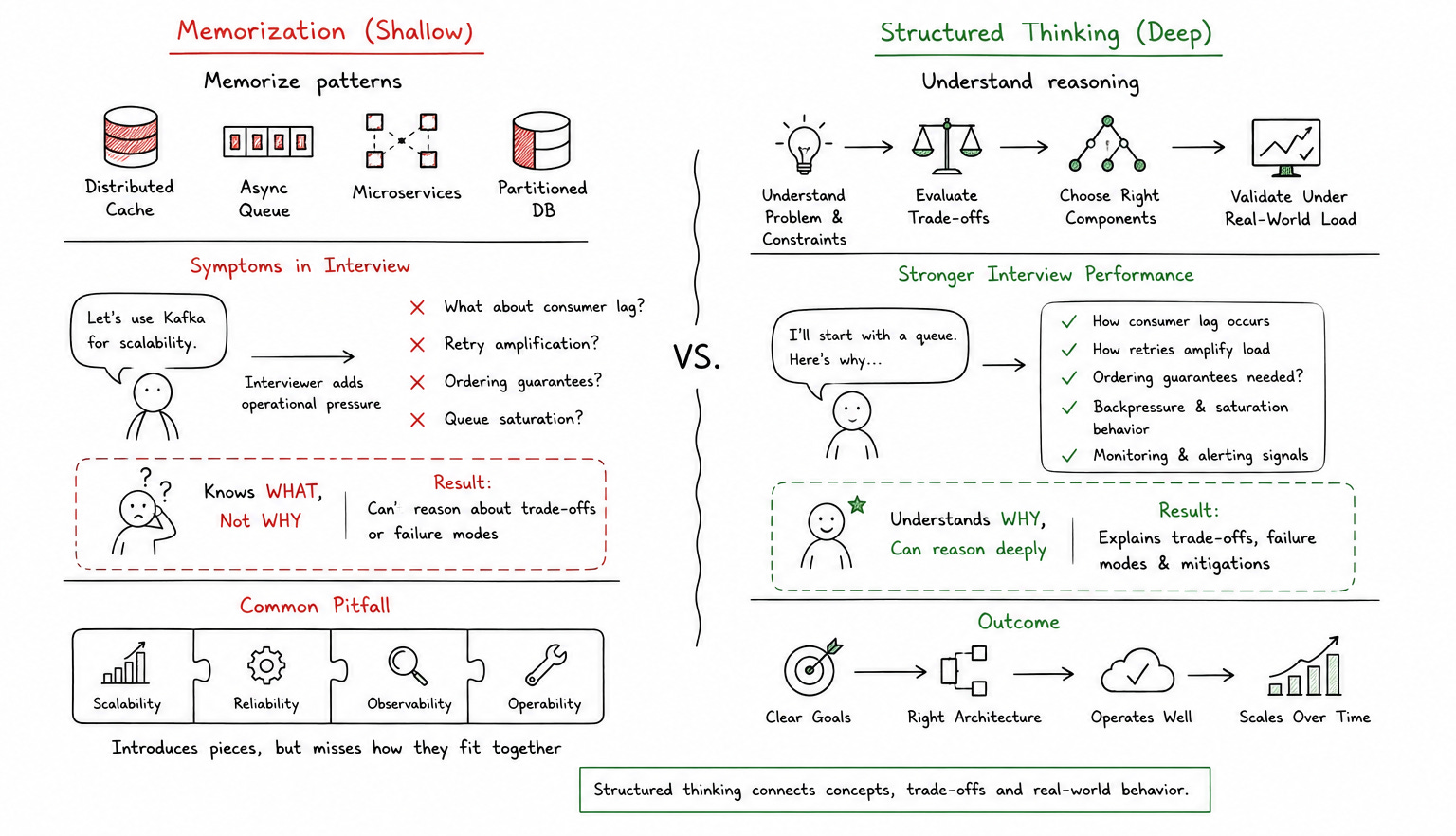
One of the problems with traditional System Design preparation is that engineers often study architecture diagrams without understanding the reasoning behind them. They memorize that companies use distributed caches, asynchronous queues, microservices, or partitioned databases, but they do not always understand why those decisions became necessary.
That creates shallow architectural reasoning.
During interviews, this usually becomes obvious once the interviewer introduces operational pressure. A candidate may propose Kafka immediately for scalability, but struggle to explain consumer lag, retry amplification, ordering guarantees, or queue saturation behavior under heavy traffic.
Similarly, candidates may introduce microservices because they sound scalable while ignoring deployment coordination, observability fragmentation, and distributed debugging complexity.
Real systems evolve incrementally
One of the ideas that shaped modern System Design interview preparation was teaching engineers to think incrementally about scale.
Large production systems rarely begin as massively distributed architectures. Most systems evolve gradually as workloads expose measurable bottlenecks. A monolithic application may eventually introduce caching because database pressure increases. Later, asynchronous processing may reduce latency for expensive workloads. Eventually, specific services may separate operationally because deployment coordination becomes too difficult.
That progression reflects reality much more accurately than designing hyperscale infrastructure from the beginning.
Once engineers begin thinking in terms of architectural evolution instead of static final-state diagrams, their interview discussions usually become much stronger because the conversation becomes grounded in operational reasoning.
The operational side of System Design interviews
One reason System Design interviews became increasingly important across the industry is that modern software systems fail differently than traditional monolithic applications.
In smaller systems, failures are often isolated and predictable. In distributed systems, failures propagate across services, queues, storage layers, and networks in ways that are difficult to reason about without understanding infrastructure behavior.
This is why experienced interviewers often push conversations toward operational scenarios instead of ideal architecture diagrams.
Systems rarely fail cleanly
Distributed systems almost never fail all at once.
Instead, they degrade gradually. Latency increases before outages appear. Queue depth grows before consumers fail. Retries amplify load against already degraded services. Replication lag introduces stale reads. Resource saturation spreads upstream as requests accumulate.
Engineers who understand these patterns naturally approach architecture differently.
Instead of discussing only how a system scales theoretically, they begin discussing how the system behaves during traffic spikes, partial failures, or infrastructure degradation.
That operational mindset is one of the defining characteristics of strong System Design interviews.
Why observability becomes part of architecture
Another concept that fundamentally changed how engineers approached System Design interviews was the realization that observability itself is part of scalable architecture.
Large systems become operationally dangerous when engineers cannot understand why they are failing.
This means strong architectures require more than load balancers and databases. They also require metrics, tracing, structured logging, and visibility into infrastructure health.
For example, understanding queue depth helps identify consumer imbalance before latency escalates. Monitoring tail latency exposes degraded dependencies hidden behind average response times. Replication lag metrics reveal consistency problems between distributed nodes.
The following table highlights operational signals that become critical as systems scale.
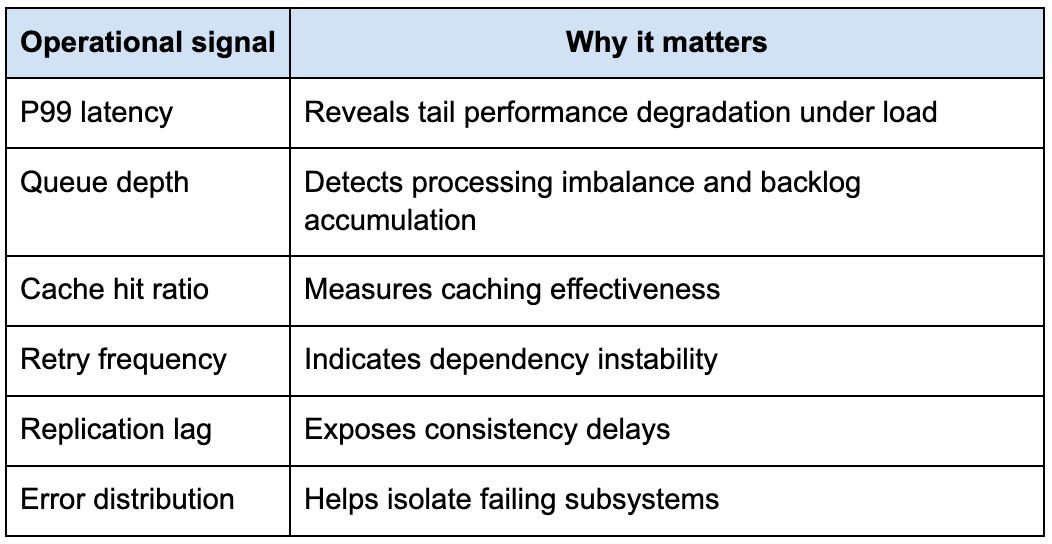
Once engineers begin thinking operationally, their System Design discussions become much more realistic.
Why scalability discussions are really tradeoff discussions
One of the biggest misunderstandings about System Design interviews is the assumption that scalability is purely about adding more infrastructure.
In reality, every scaling decision introduces tradeoffs.
Caching reduces latency but introduces stale data risks. Replication improves read throughput but creates synchronization complexity. Partitioning increases scalability but complicates routing and rebalancing. Asynchronous processing improves throughput but weakens consistency guarantees.
Strong engineers recognize these tradeoffs naturally instead of presenting infrastructure decisions as universally correct.
The danger of premature complexity
One of the recurring patterns across modern distributed systems is that complexity often arrives earlier than necessary.
Engineers sometimes introduce distributed infrastructure because it feels architecturally sophisticated rather than because the workload genuinely requires it. The problem is that every additional service, queue, cache, or coordination layer increases operational overhead.
Microservices require deployment coordination. Distributed queues require retry management. Event-driven systems complicate debugging. Partitioned databases create balancing challenges.
Experienced engineers understand that complexity itself becomes a scaling constraint over time.
This is why mature architectural reasoning usually favors simpler systems until measurable bottlenecks justify additional infrastructure.
Why communication matters as much as technical depth
A surprising number of System Design interviews are not derailed by poor architecture, but by unclear communication.
As systems grow more complex, explanations become harder to follow. Candidates jump between caching layers, storage systems, queues, APIs, replication strategies, and scaling logic without guiding the interviewer through the architecture coherently.
Strong System Design discussions usually evolve in layers.
The engineer first establishes the core requirements. Then they define the baseline architecture. Afterward, they expand the system gradually in response to scaling constraints or reliability requirements.
That layered communication style makes even complex architectures easier to understand.
Good System Design interviews feel collaborative
One of the reasons structured preparation approaches became valuable is that they helped engineers understand the rhythm of System Design interviews.
The best interviews rarely feel like interrogations. Instead, they resemble collaborative architecture reviews where the interviewer introduces constraints progressively and evaluates how the engineer adapts the system.
This creates a very different dynamic from coding interviews.
The interviewer may suddenly increase traffic assumptions, introduce regional failures, add consistency requirements, or explore cost constraints midway through the discussion. Strong engineers remain calm because they treat architecture as an evolving set of tradeoffs rather than a fixed diagram.
That adaptability is often what separates senior-level System Design performance from memorized answers.
Why distributed systems thinking changes engineering itself
One of the most interesting outcomes of structured System Design preparation is that it often changes how engineers think about software architecture long after interviews end.
Once engineers begin studying scalability and operational behavior deeply, they start approaching engineering decisions differently in day-to-day development work.
They become more careful about introducing unnecessary infrastructure. They think more critically about bottlenecks before scaling systems prematurely. They value observability earlier in the development lifecycle. They recognize that every abstraction introduces operational consequences.
This shift in thinking is important because modern software systems increasingly operate under distributed environments where infrastructure decisions influence reliability, latency, scalability, and team velocity simultaneously.
The lasting impact of Grokking System Design interview
One reason Grokking the System Design Interview became influential is that it helped engineers organize a subject that previously felt chaotic and intimidating.
System Design interviews are difficult, not because the concepts themselves are impossible to learn, but because they require combining multiple engineering disciplines simultaneously. Networking, storage systems, distributed coordination, scalability, observability, reliability, and operational tradeoffs all intersect inside the same conversation.
Providing engineers with a structured way to reason through those systems made large-scale architecture more approachable.
More importantly, it helped engineers shift from memorizing distributed systems terminology toward understanding how systems evolve under real operational pressure.
That mindset ultimately matters far beyond interviews themselves because scalable engineering has never been about drawing the most complicated architecture diagram. It has always been about understanding constraints clearly enough to make deliberate technical decisions under uncertainty.