

Here’s how to think in intelligent systems for your OpenAI System Design interview
How to approach OpenAI System Design interviews by thinking in LLM systems, APIs, and real-world AI infrastructure constraints

If you approach an OpenAI System Design interview with the same mental model you would use for a traditional distributed systems problem, you will likely produce something that looks structurally correct but misses the defining constraint of the system you are designing. The difference is not that concepts like scalability, availability, and fault tolerance stop mattering. The difference is that the core unit of computation is no longer deterministic logic executed over structured data, but probabilistic inference over large models that operate on tokens, context, and learned representations.
This changes the shape of every design decision. In most backend systems, the complexity comes from coordinating services and managing data consistency. In OpenAI-style systems, the complexity emerges from orchestrating model inference, managing context windows, optimizing cost and latency, and ensuring that outputs remain safe and useful under a wide range of inputs. The model is not just a component in the system. It is the center of gravity around which the rest of the architecture is built.
The System Design interview is not testing whether you can deploy a model behind an API. It is testing whether you understand how to design systems that expose intelligence reliably, at scale, under real-world constraints that are often invisible in simplified diagrams.
The nature of systems OpenAI builds
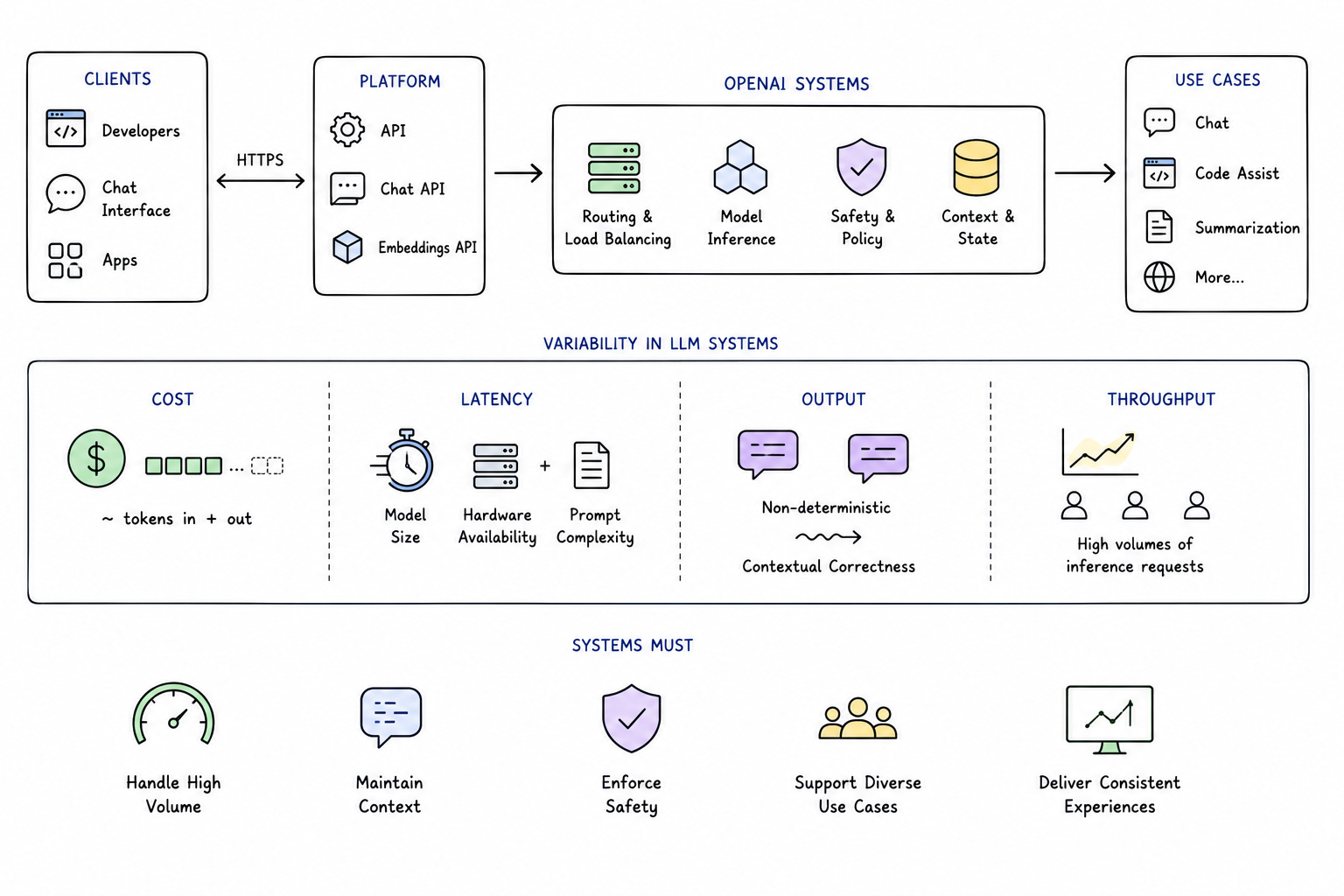
To understand how to tackle OpenAI System Design interview questions, it helps to ground your thinking in the types of systems they operate. At a high level, OpenAI builds platforms that allow developers and end users to interact with large language models through APIs, chat interfaces, and embedded applications. These systems must handle high volumes of inference requests, maintain conversational context, enforce safety policies, and deliver consistent experiences across diverse use cases.
Unlike traditional backend systems, where compute cost is relatively stable and predictable, LLM systems introduce variability at multiple layers. The cost of a request depends on the number of tokens processed and generated. The latency depends on model size, hardware availability, and prompt complexity. The output itself is non-deterministic, which means that correctness is not binary but contextual.
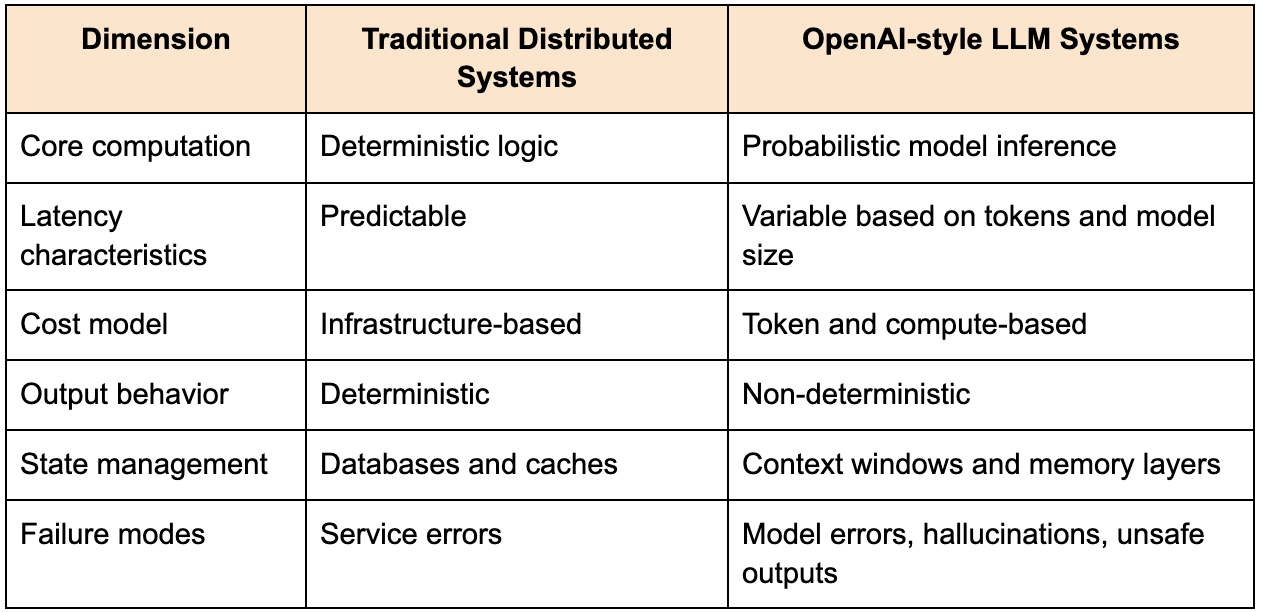
The table below highlights how OpenAI-style systems differ from traditional distributed systems:
This distinction is critical because it shifts the focus of System Design. You are no longer optimizing only for throughput and latency. You are also optimizing for response quality, safety, and cost efficiency.
How OpenAI frames System Design problems
OpenAI System Design interviews often revolve around problems such as designing a chat assistant, building an API for text generation, or creating a system that answers questions over documents. These problems may sound similar to other LLM-related interview questions, but the depth lies in how you reason about system behavior at scale.
The interviewer is not just evaluating whether you can connect a frontend to a model endpoint. They are evaluating how you think about prompt construction, context management, safety enforcement, and system reliability. They want to see whether you understand how these systems behave when usage grows, when inputs become unpredictable, and when costs begin to matter.
A strong answer begins by acknowledging that the model is not a black box you can ignore. It is the most expensive, complex, and most unpredictable part of the system, and everything else exists to make its usage efficient and reliable.
A representative problem: designing an LLM-powered assistant
Consider a scenario where you are asked to design a system similar to ChatGPT. At a high level, the system must accept user input, generate responses using a large language model, and maintain conversational context.
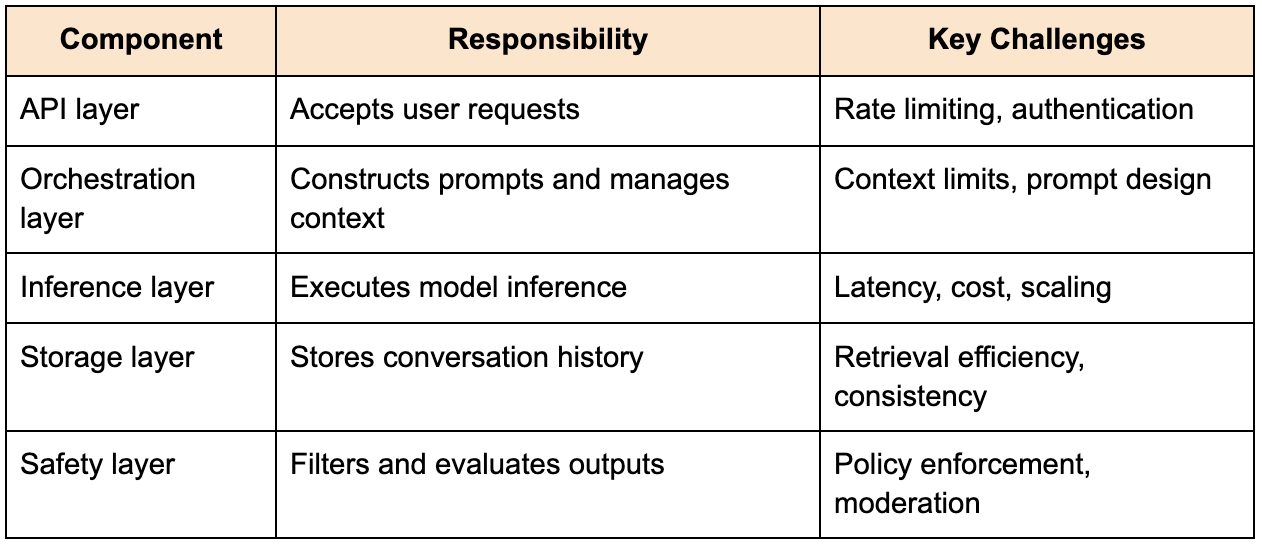
The table below outlines the core components of such a system:
At first glance, this architecture may resemble a typical service-oriented design, but the complexity becomes evident when you consider how these components interact under real-world conditions.
Context management: the core system constraint
One of the most important aspects of LLM systems is context management. Unlike traditional systems, where state is stored explicitly and can be queried independently, LLMs rely on context windows that have strict limits.
This means that every request to the model must include all relevant information needed to generate a response. The system must decide what to include and what to omit, balancing completeness against token limits and cost.
This introduces a unique design challenge. Including more context improves response quality but increases cost and latency. Including less context reduces cost but may degrade the usefulness of the output.
To address this, systems often use techniques such as summarization, retrieval augmentation, and context pruning. These techniques allow the system to maintain relevant information while staying within constraints.
The challenge is that these decisions are dynamic. The optimal context for one request may not be optimal for another, and the system must adapt accordingly.
Latency and cost: inseparable trade-offs
In OpenAI-style systems, latency and cost are tightly coupled. Generating more tokens increases both latency and cost, and using larger models amplifies this effect.
This creates a design environment where every decision has both performance and financial implications. A system that delivers high-quality responses but at unsustainable cost is not viable. Similarly, a system that optimizes cost at the expense of quality may fail to meet user expectations.
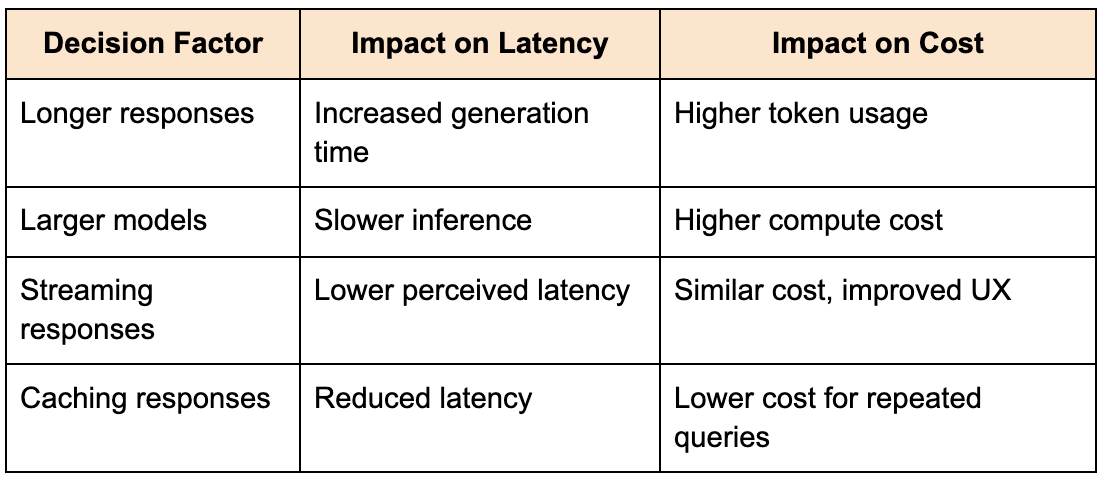
The table below illustrates common trade-offs:
What makes these trade-offs challenging is that they are not static. As usage patterns change, the system must adapt its strategies to maintain efficiency.
Orchestration: more than just routing requests
In traditional systems, orchestration often involves routing requests between services. In LLM systems, orchestration is significantly more complex. It involves constructing prompts, selecting models, managing context, and handling retries.
For example, a single user request may involve multiple steps, such as retrieving relevant documents, summarizing them, and then generating a response. Each step adds latency and cost, but may be necessary to achieve the desired output quality.
This means that orchestration is not just about connectivity. It is about optimizing the sequence of operations to balance quality, cost, and performance.
Safety and moderation as system requirements
One of the defining aspects of OpenAI systems is the emphasis on safety. Outputs must adhere to policies that prevent harmful or inappropriate content, and this requirement must be enforced consistently across all interactions.
This introduces an additional layer in the system architecture. Outputs must be evaluated and filtered before being returned to the user. In some cases, inputs may also need to be sanitized or rejected.
The challenge is that safety mechanisms can introduce latency and complexity. Running additional checks on every response increases processing time, but skipping these checks can lead to unacceptable outcomes.
This is not a trade-off that can be ignored. Safety is a core requirement, and the system must be designed to enforce it reliably.
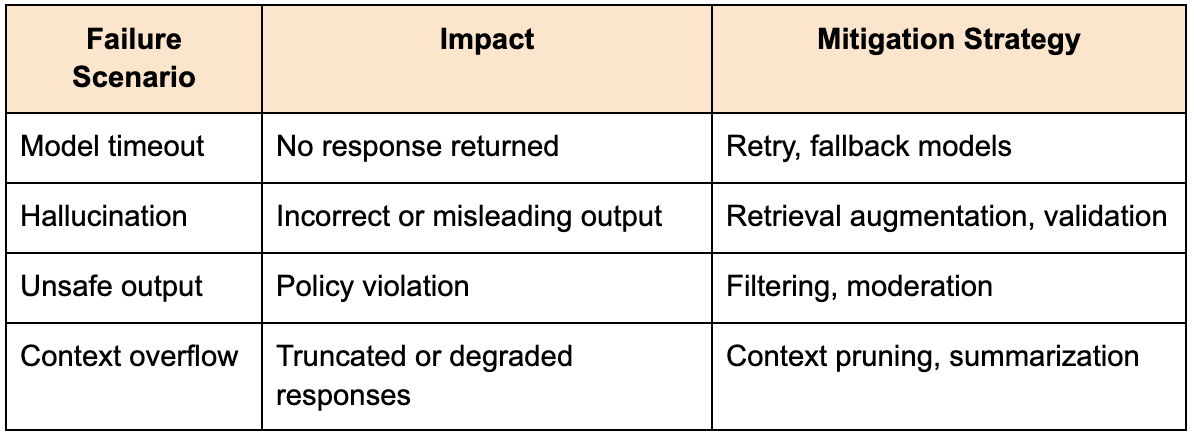
Handling failures in LLM systems
Failures in LLM systems extend beyond traditional infrastructure issues. In addition to timeouts and service errors, you must consider model-specific failures such as hallucinations, incomplete responses, and unsafe outputs.
A robust system must include mechanisms to detect and mitigate these issues. This may involve validating outputs, retrying requests with modified prompts, or falling back to alternative models.
The table below outlines common failure scenarios:
These failures are often subtle and difficult to detect, which makes proactive design essential.
Scaling inference systems
Scaling an OpenAI-style system involves more than adding servers. It requires managing computationally intensive workloads that depend on specialized hardware such as GPUs.
This introduces challenges around resource allocation, scheduling, and load balancing. The system must ensure that inference requests are distributed efficiently while maintaining low latency.
The table below outlines common bottlenecks:
These challenges require careful coordination between infrastructure and application layers.

Observability in AI systems
Observability in LLM systems goes beyond traditional metrics such as latency and error rates. You must also monitor output quality, safety compliance, and user satisfaction.
This requires collecting data at multiple levels, including request metrics, model outputs, and user interactions. Without this visibility, it becomes difficult to diagnose issues or improve the system.
The challenge is that quality and safety are not easily measurable. They require additional evaluation mechanisms, which must be integrated into the system.
Structuring your answer in the interview
When presenting your design, it is important to structure your explanation around the lifecycle of a request. Start by defining the requirements and constraints, then describe how the system processes inputs, interacts with the model, and returns outputs.
Instead of focusing solely on infrastructure, emphasize how the model is integrated into the system. This includes context management, orchestration, and safety mechanisms.
Your design should evolve naturally as you introduce constraints. Each component should address a specific challenge, and each trade-off should be explained clearly.
What OpenAI is really evaluating
At its core, the OpenAI System Design interview evaluates your ability to design systems that integrate intelligence into real-world applications. It is testing whether you understand how to manage complexity, uncertainty, and cost while delivering reliable and useful outputs.
The strongest candidates are those who can reason about trade-offs, justify their decisions, and adapt their designs based on evolving requirements. They are not just applying patterns, but understanding how those patterns behave in the context of AI systems.
Final perspective
Designing systems for OpenAI requires a shift in mindset from deterministic systems to probabilistic systems. It requires an understanding of how models behave, how context is managed, and how systems can be designed to deliver reliable outputs despite inherent uncertainty.
If you approach the interview with this perspective, the complexity becomes more manageable. Instead of trying to design the most sophisticated system, focus on designing a system that is grounded in real-world constraints and capable of evolving as those constraints change.