

How I’d learn System Design from scratch if I had to start over today
A realistic roadmap for engineers who want to understand scalable systems deeply

Most developers approach System Design the wrong way in the beginning. They open YouTube videos about distributed systems, watch someone draw a few boxes labeled “API Gateway,” “Kafka,” and “Redis,” and then assume they are learning architecture.
A few weeks later, they realize they still cannot explain why a cache should exist, when sharding becomes necessary, or how latency compounds across services. The problem is not intelligence. The problem is the sequence.
System Design only starts making sense when you learn it in the same order real systems evolve in production. That means understanding constraints before patterns, bottlenecks before technologies, and trade-offs before scalability buzzwords.
If I had to learn System Design from scratch today, I would ignore most of the noise online and focus on building a mental model for how systems behave under real traffic, real failures, and real operational pressure.
Why most engineers struggle to learn System Design
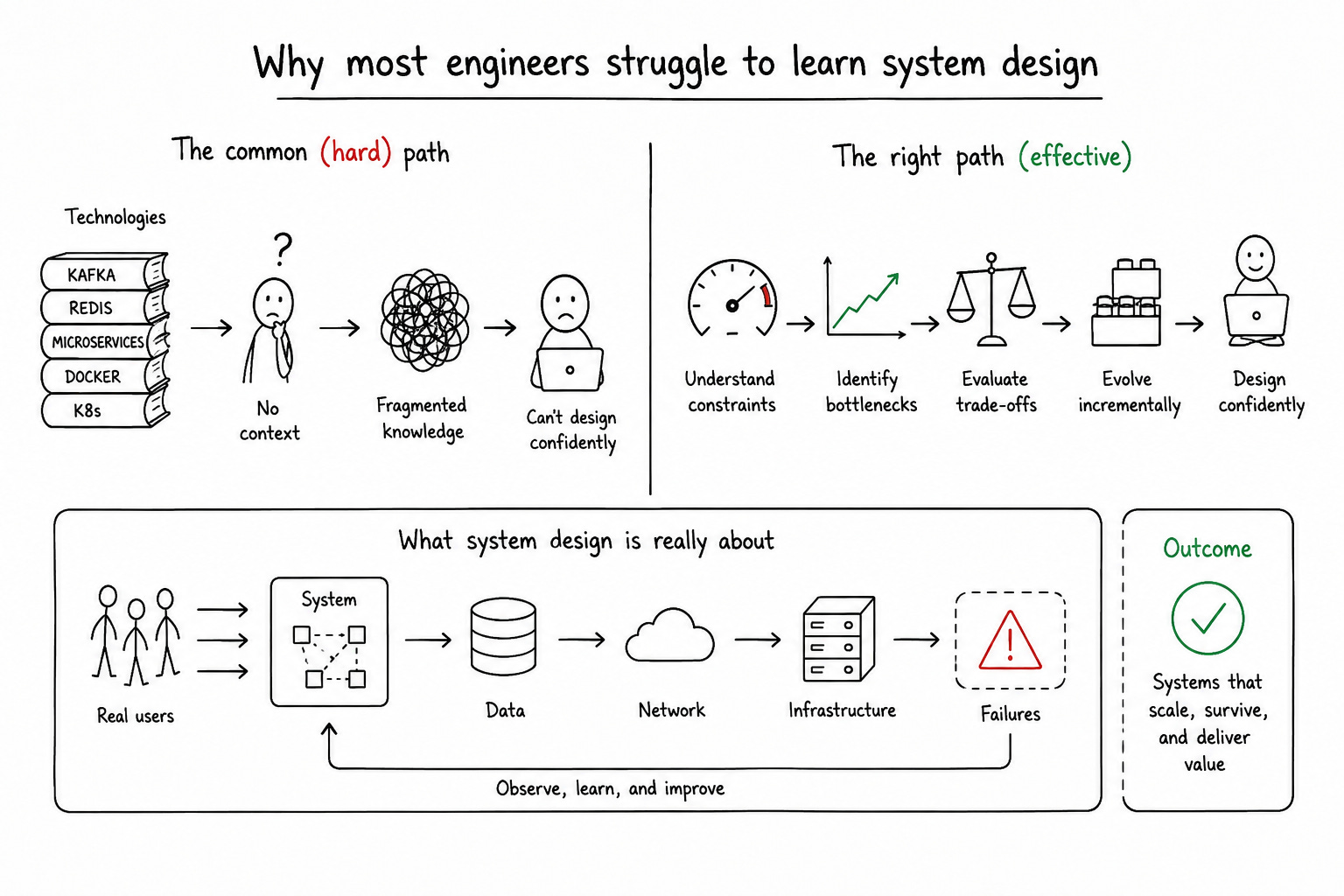
One of the biggest misconceptions about System Design is that it is an advanced topic reserved for senior engineers working on infrastructure teams. In reality, System Design is simply the study of how software behaves once real users start interacting with it at scale. The reason it feels intimidating is that most developers encounter it through interview questions rather than through gradual exposure in production systems.
When someone asks you to design YouTube, Instagram, or Uber, they are not actually testing whether you can reproduce the exact architecture used inside those companies. They are evaluating whether you understand how systems respond to increasing load, conflicting requirements, infrastructure limitations, and failure conditions. Good System Design is less about memorizing architecture diagrams and more about understanding why specific decisions become necessary.
That distinction matters because most online learning resources overload beginners with technologies before teaching the underlying constraints those technologies solve. Engineers start learning Kafka before they understand asynchronous processing. They memorize Redis use cases before understanding database latency. They jump into microservices before they have ever seen a monolith fail under scale. That approach creates fragmented knowledge instead of architectural intuition.
I have interviewed hundreds of candidates across Microsoft, Meta, and Educative, and the strongest System Design candidates were rarely the people who knew the most terminology. They were the people who could reason calmly through bottlenecks, explain trade-offs clearly, and evolve systems incrementally instead of over-engineering them from the beginning.
The learning process should reflect that reality.
Start with how requests actually move through systems
Before you study distributed systems, you need to understand the lifecycle of a single request. Most beginner engineers skip this phase because it feels too basic, but this is where architectural intuition starts forming.
Every scalable system is ultimately processing requests moving through compute, storage, memory, and networks. If you do not understand how those layers interact, System Design diagrams become abstract shapes rather than engineering decisions.
The first thing I would study is how a browser request travels through the internet and reaches an application server. That means understanding DNS resolution, TCP connections, HTTPS handshakes, load balancers, reverse proxies, application servers, databases, and caching layers. Once you understand the request lifecycle, scalability problems stop feeling mysterious because you can identify where latency accumulates and where resources become constrained.
The following table represents the foundational concepts I would learn before touching advanced distributed systems topics.
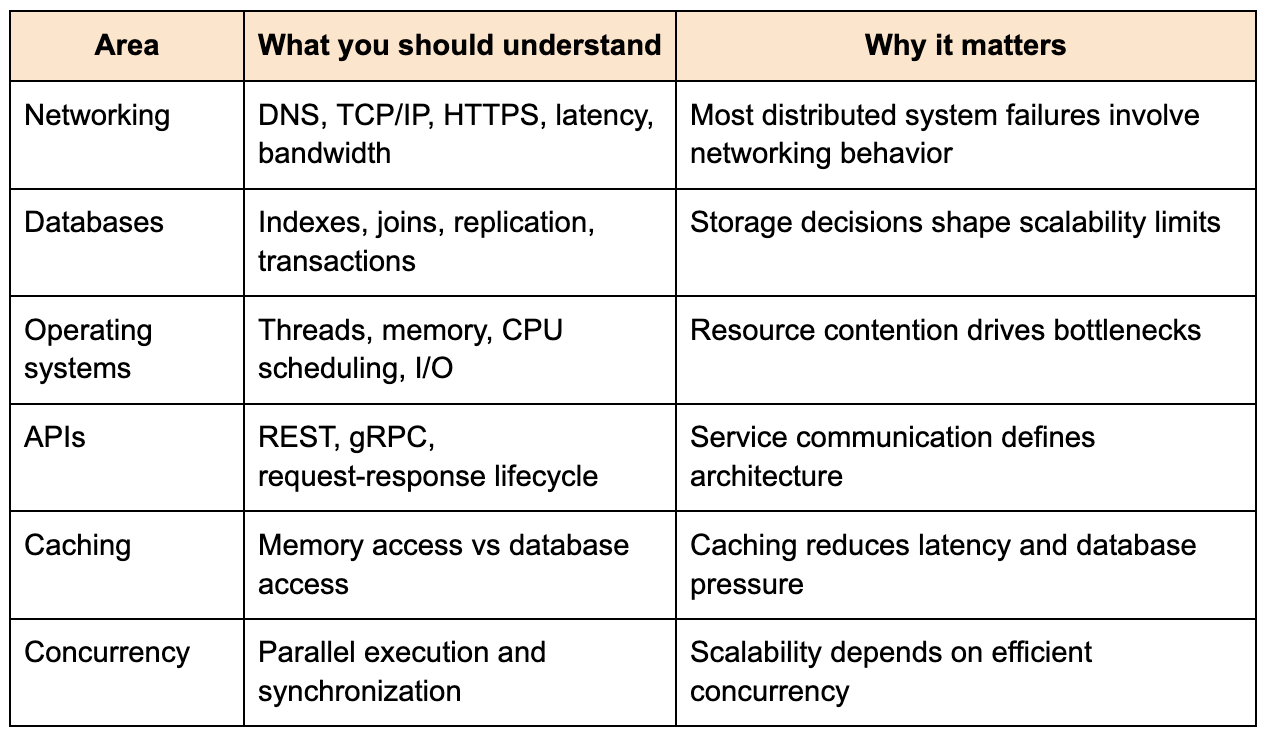
Most beginner roadmaps focus almost entirely on architecture patterns. The stronger approach is to first understand the mechanics beneath those patterns. A load balancer only matters once you understand why a single server becomes saturated. Replication only matters once you understand why read throughput overwhelms a primary database.
This is also why blindly copying “FAANG architecture diagrams” is usually counterproductive for beginners. Those systems evolved over years of measured traffic growth. Without understanding the underlying constraints, you are memorizing outputs without understanding inputs.
Learn databases before distributed systems
If I could change one thing about how engineers learn System Design, it would be forcing them to spend significantly more time understanding databases before moving into distributed architectures.
Most scalability problems eventually become data problems.
At a small scale, databases feel invisible because modern frameworks abstract them away. Queries execute quickly, relational joins work naturally, and developers rarely think about indexing strategy. Once traffic increases, databases become the center of nearly every architectural conversation.
That is why I believe every beginner learning System Design should first become comfortable reasoning about storage models, indexing, replication, partitioning, and consistency.
A surprising number of engineers try to learn microservices before they can explain why a database query becomes slow. That sequence creates shallow architectural understanding because distributed systems exist largely to manage scaling pressure around computation and storage.
The table below represents the progression I would follow when learning data systems.
Once you understand how data behaves under scale, System Design decisions start feeling rational instead of arbitrary.
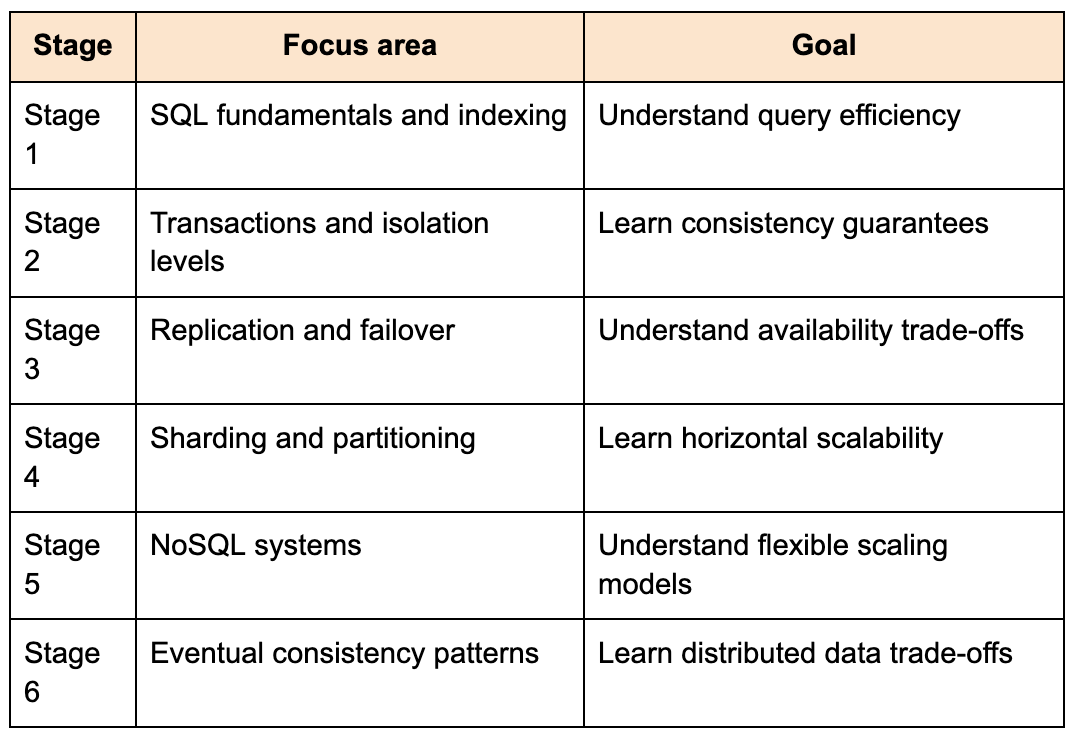
For example, engineers often hear that NoSQL databases are “better for scale,” but that statement is incomplete without understanding trade-offs. Many NoSQL systems achieve scalability by sacrificing strong consistency guarantees, relational querying flexibility, or transactional support. Without understanding those trade-offs, database selection becomes cargo-cult engineering.
The strongest System Designers think in constraints rather than technologies.
Stop trying to learn microservices too early
One of the most damaging trends in modern software education is the obsession with microservices before engineers understand monolithic systems.
I have seen early-stage startups with fewer than 5,000 daily users deploy Kubernetes clusters, service meshes, distributed tracing pipelines, and event-driven architectures before validating whether their product even needed that operational complexity. In many cases, engineers were solving hypothetical scalability problems while introducing real reliability problems.
A modular monolith is one of the best environments for learning System Design because it allows you to study architectural boundaries without inheriting the operational complexity of distributed systems.
Inside a monolith, requests remain local function calls rather than remote network calls. Observability is simpler because logs, traces, and metrics are centralized. Debugging is faster because there are fewer infrastructure variables. Most importantly, bottlenecks become easier to isolate.
That simplicity accelerates learning.
The following comparison highlights why I believe beginners should delay microservices until they understand monolithic scaling behavior.
This does not mean microservices are bad. They become valuable once measurable scaling pressure justifies distribution. The problem is that many engineers learn distributed systems through architecture aesthetics rather than production constraints.
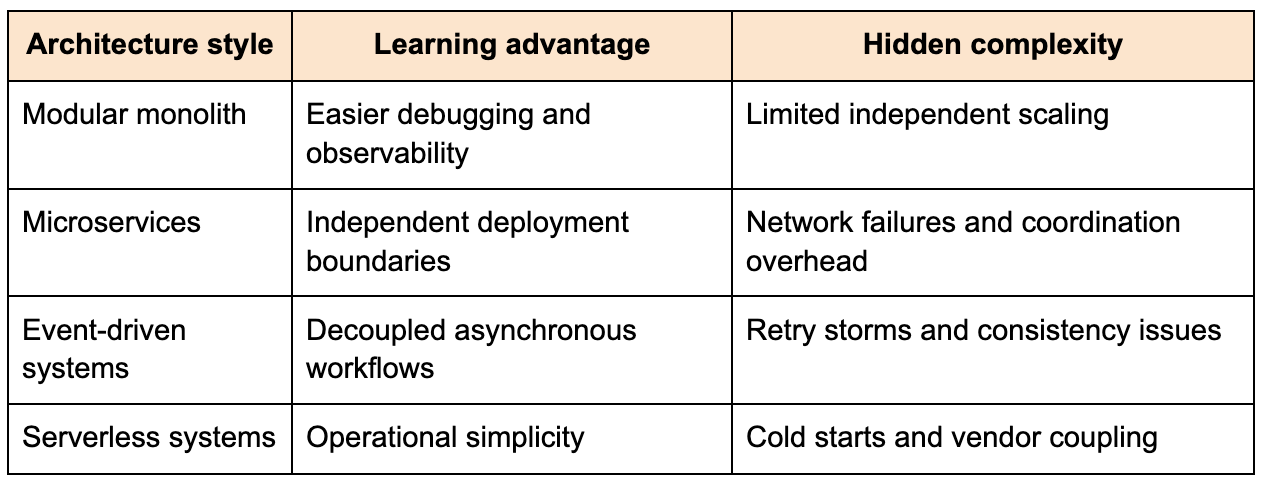
A service boundary introduces serialization costs, network latency, retry policies, timeout management, distributed tracing requirements, and operational coordination overhead. Those costs are worthwhile when independent scaling or organizational isolation becomes necessary. They are not free.
Understanding that distinction is one of the most important mindset shifts in System Design.
Study real systems instead of memorizing interview templates
Most engineers eventually realize that System Design interviews follow recurring patterns. URL shorteners introduce hashing and redirection. Chat systems introduce message ordering and fan-out. Social media feeds introduce caching and timeline generation.
The danger is turning those patterns into memorized scripts.
Strong System Designers study why architectural decisions emerged in real production systems. That means reading engineering blogs, postmortems, scalability breakdowns, and infrastructure retrospectives.
Netflix engineering blogs are useful not because you will recreate Netflix infrastructure, but because they explain why distributed systems evolve under production constraints. Uber engineering posts reveal how operational bottlenecks force architectural adaptation. Meta infrastructure articles demonstrate how observability and data systems evolve under massive concurrency.
When you study systems this way, architecture becomes a sequence of engineering responses rather than a static diagram.
One of the most valuable exercises for beginners is analyzing the same application at different scales.
A chat application serving 1,000 users looks dramatically different from one serving 100 million concurrent users. At a low scale, polling might be sufficient. On a larger scale, persistent WebSocket connections become necessary. Database replication may become insufficient once write contention increases. Caching strategies evolve. Queue systems emerge. Data partitioning becomes necessary.
That evolution teaches you something important.
System Design is not about building the final architecture immediately. It is about understanding how systems change as constraints shift.
Learn to think in bottlenecks
The best System Designers I have worked with shared one consistent trait: they thought constantly about bottlenecks.
They did not begin discussions by suggesting technologies. They began by asking what resource was becoming constrained.
Was CPU utilization saturating during peak traffic? Were database connections exhausted under concurrency spikes? Was tail latency increasing because requests remained blocked on slow downstream dependencies? Was memory pressure triggering garbage collection pauses?
That bottleneck-oriented thinking is what separates architectural reasoning from technology memorization.
Most beginner engineers think scaling means “adding servers.” Real scalability work is usually about identifying which component saturates first and why.
For example, consider a content feed system. At a small scale, generating feeds dynamically during requests may work perfectly well. As user growth increases, database queries may become too expensive under heavy read traffic. Engineers introduce caching layers. Eventually cache invalidation complexity emerges because content updates become difficult to synchronize efficiently. Fan-out strategies evolve. Background processing pipelines emerge.
The architecture changes because the bottlenecks change.
This is also why observability matters so much in System Design learning.
Without metrics, you are guessing.
I strongly recommend that engineers learning System Design spend time understanding monitoring dashboards, latency percentiles, throughput graphs, queue depth metrics, and saturation signals. Averages are rarely enough because tail latency drives user-visible failures.
Understanding the difference between P50 latency and P99 latency is more valuable than memorizing dozens of distributed systems patterns.
Build small systems before designing giant ones
One of the fastest ways to accelerate System Design learning is to build systems slightly beyond your current comfort zone.
Do not begin with “Design YouTube.” Begin with smaller systems that force you to confront real architectural decisions.
Build a URL shortener with rate limiting. Build a chat application using WebSockets. Build a notification system with asynchronous queues. Build a search engine with indexing. Build a file upload service with chunked storage.
The goal is not production perfection.
The goal is to learn how architectural decisions emerge from practical engineering constraints.
When you build these systems yourself, concepts stop feeling theoretical.
You start seeing how database indexing affects response time. You experience how synchronous processing slows user-facing APIs. You encounter retry behavior during network failures. You understand why observability matters once debugging becomes painful.
That hands-on learning creates intuition far faster than passive content consumption.
This is also why I generally advise against spending months consuming endless “System Design interview answers” without implementation experience. Without an implementation context, architectural discussions remain shallow because you have never experienced the operational trade-offs personally.
Understand trade-offs instead of searching for perfect answers
One of the hardest mental shifts in System Design is accepting that there are rarely perfect solutions.
Every architecture decision introduces trade-offs.
Caching improves latency but introduces invalidation complexity. Replication improves availability but creates consistency challenges. Partitioning improves scalability but complicates querying. Microservices improve independent deployment flexibility but increase operational overhead.
That trade-off thinking is the foundation of mature System Design.
Many beginners approach System Design as if there is always a “correct architecture.” In reality, good System Design depends heavily on context.
A startup optimizing for rapid iteration may prioritize simplicity over theoretical scalability. A financial system may prioritize consistency over availability. A streaming platform may tolerate eventual consistency in exchange for throughput efficiency.
The architecture follows the constraints.
This is why interviewers care more about reasoning than final diagrams.
When I interviewed engineers at Microsoft and Meta, the strongest candidates were not necessarily the people who proposed the most advanced architectures. They were the people who explained their trade-offs clearly, adapted calmly when assumptions changed, and demonstrated awareness of operational consequences.
That mindset is difficult to fake because it usually reflects real engineering maturity.
A realistic roadmap for learning System Design from scratch
If I were starting over today, this is the sequence I would follow.
I would spend the first few weeks learning networking fundamentals, request lifecycles, database indexing, caching behavior, and concurrency basics. During this phase, the objective would not be memorization. The objective would be to develop intuition around how requests move through systems and where latency accumulates.
The next phase would focus heavily on databases and storage systems because scalable architectures are ultimately shaped by data access patterns. I would study replication, transactions, partitioning, eventual consistency, and query optimization before touching advanced distributed architectures.
After that, I would begin studying real-world architectures gradually rather than jumping immediately into giant systems. I would analyze URL shorteners, chat applications, file storage systems, and feed generation systems while focusing on how those architectures evolve under increasing traffic.
Only after developing comfort with those foundations would I spend serious time learning distributed systems patterns such as queues, event-driven architectures, stream processing, and microservices.
The sequence matters because architectural maturity develops incrementally.
You cannot reason about distributed systems effectively until you understand the constraints distributed systems are attempting to solve.
The biggest mistake beginners make
The most common mistake I see is treating System Design as an interview subject instead of an engineering discipline.
When engineers optimize exclusively for interview performance, they often memorize architecture templates without developing real operational understanding. That works temporarily for surface-level conversations, but it collapses quickly once discussions become deeper.
Real System Design learning happens when you become curious about how production systems behave.
Why did this database become saturated? Why did retries amplify a partial outage? Why did the queue depth spike during peak traffic? Why did latency increase even though CPU usage remained low?
Those questions build engineering judgment.
System Design is ultimately the study of constraints, trade-offs, and failure behavior under scale. Once you understand that, architecture diagrams stop feeling abstract and start feeling inevitable.
That is the point where System Design finally becomes intuitive.
Learn systems gradually, not performatively
The internet often makes System Design feel like a competition to sound sophisticated. Engineers rush to talk about distributed tracing, event sourcing, CQRS, Kubernetes orchestration, and multi-region failover before they fully understand database indexing or request latency.
That approach slows learning.
The strongest systems are usually evolved incrementally from simple foundations. They become distributed because scale forces distribution, not because engineers wanted more complicated diagrams.
If I had to learn System Design from scratch again, I would spend far less time trying to sound architectural and far more time understanding how systems behave under measurable load. I would prioritize debugging bottlenecks over memorizing buzzwords, studying production trade-offs over collecting interview templates, and building small systems over obsessing about giant ones.
Because in the end, scalable architecture is rarely about predicting the future perfectly.
It is about understanding the system you have well enough to evolve it when the pressure finally arrives.