

Slack System Design: What actually happens when a message is sent
Breaking down how real-time messaging systems handle latency, fan-out delivery, and massive concurrent connections

At first glance, Slack appears deceptively simple. A user types a message, presses enter, and the message appears instantly for everyone in the channel. That simplicity hides the reality that Slack is fundamentally a real-time distributed system with strict expectations around latency, ordering, durability, and fan-out delivery. The moment you stop thinking of Slack as a messaging app and start thinking of it as a coordination system operating at a global scale, the design constraints begin to surface.
One of the most common mistakes I have seen when engineers approach Slack System Design is that they focus too early on components like message queues or WebSocket clusters without first understanding the lifecycle of a single message. That mistake mirrors the same pattern described in your sample, where systems are designed for hypothetical scale instead of observed behavior, and the result is often unnecessary complexity before any real constraints appear.
The more useful approach is to start with a single message and trace its path through the system, identifying where latency is introduced, where state is persisted, and where failure can occur. Only then does it make sense to reason about scaling strategies.
The lifecycle of a message in Slack
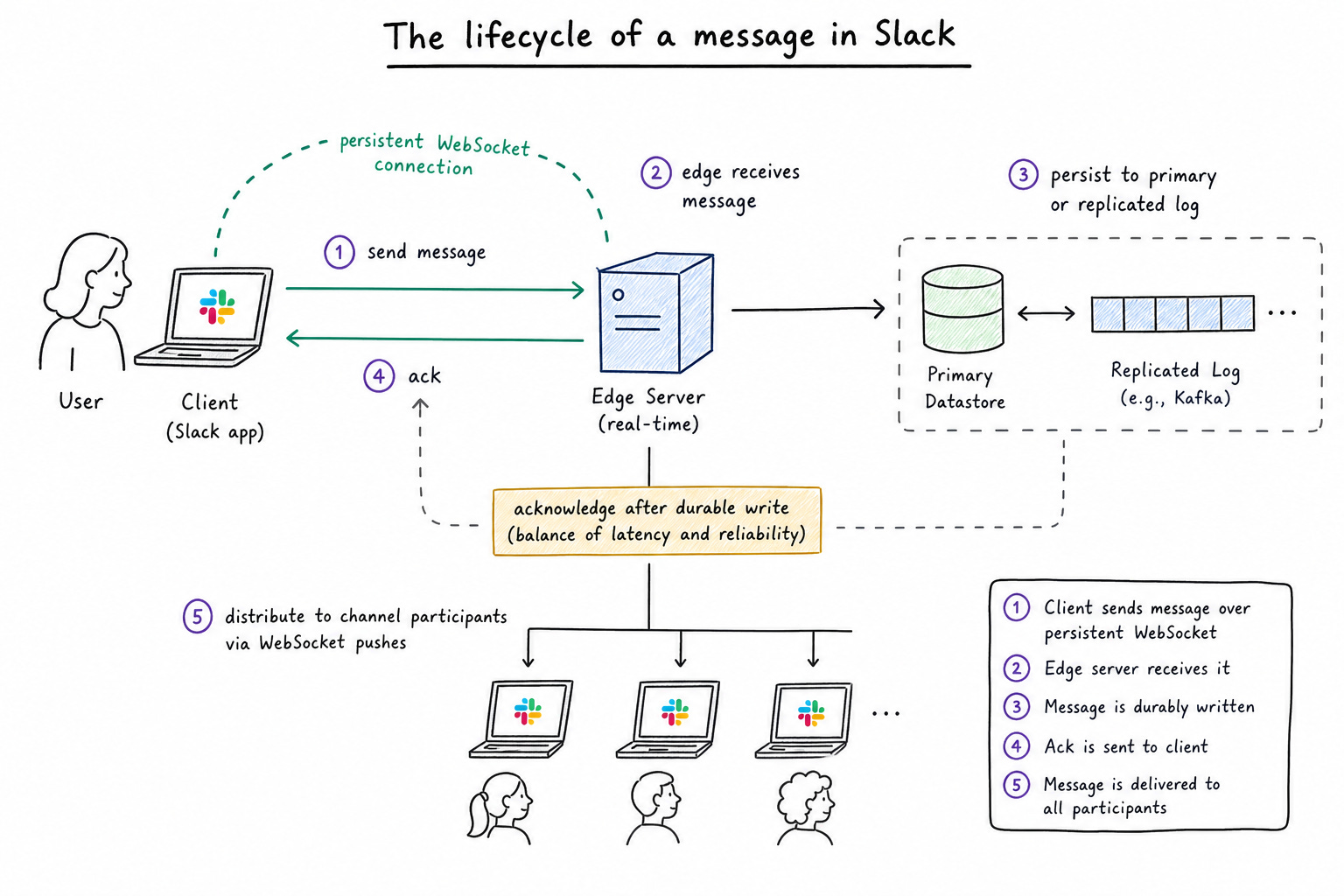
When a user sends a message in Slack, the system is not simply storing text and broadcasting it. It is performing a sequence of operations that must balance speed with consistency. The user expects near-instant delivery, but the system must also guarantee that messages are durable, ordered correctly within a channel, and eventually delivered to all participants.
The flow begins with the client, which maintains a persistent WebSocket connection to Slack’s backend. This connection is critical because it eliminates the overhead of repeated HTTP requests and allows the server to push updates in real time. When the user sends a message, the client transmits it over this connection to an edge server responsible for handling real-time traffic.
At this point, the system must make an early decision about acknowledgment. If Slack waits for the message to be fully persisted and distributed before acknowledging the client, latency increases significantly. If it acknowledges too early, there is a risk of message loss in failure scenarios. In practice, systems like Slack tend to acknowledge once the message is durably written to a primary datastore or a replicated log, ensuring a balance between responsiveness and reliability.
Core components and responsibilities
To understand how Slack maintains this balance, it helps to break the system into logical components, while keeping in mind that these boundaries are conceptual rather than strictly tied to separate services in the early stages of design.
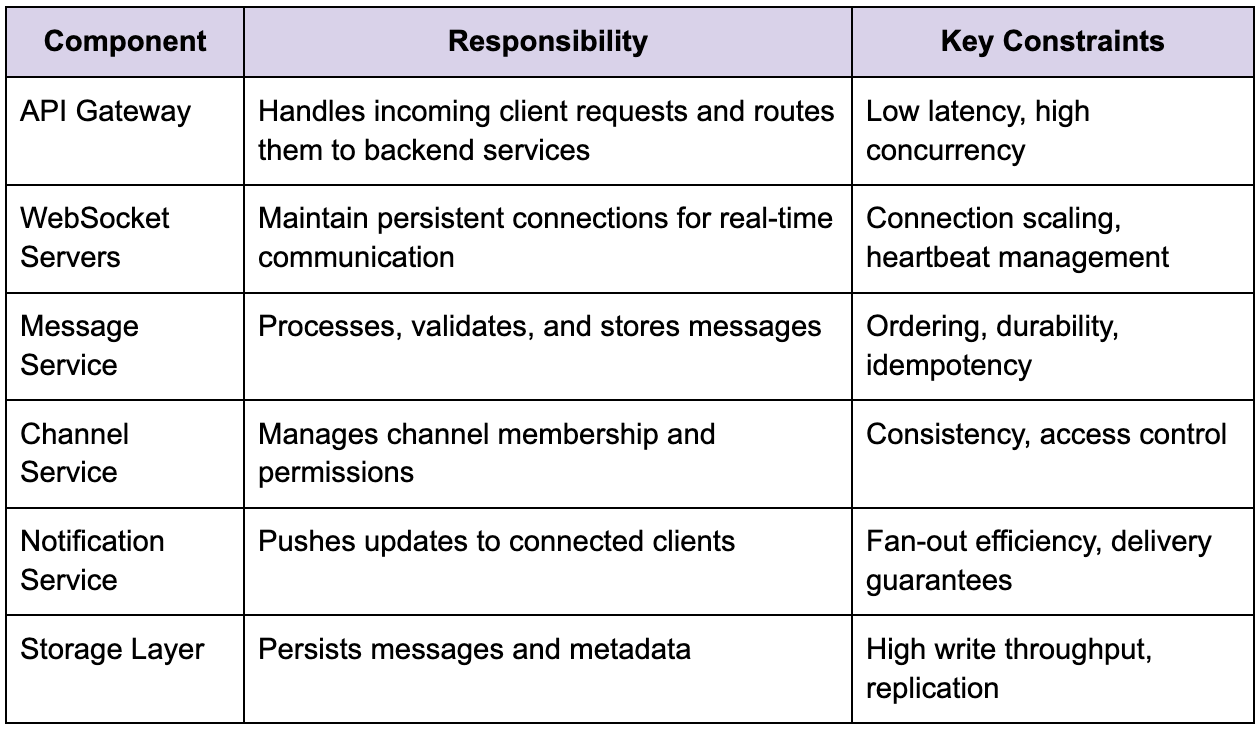
This separation is useful for reasoning, but it is important to resist the temptation to prematurely distribute these components into independent services. As highlighted in your sample, introducing network boundaries too early replaces simple function calls with RPC overhead, which adds latency and failure modes without a clear benefit.
Real-time delivery and WebSocket scaling
The most defining characteristic of Slack is its real-time nature, and this is where WebSocket infrastructure becomes central to the design. Each active user maintains a persistent connection to the backend, which means the system must handle millions of concurrent open connections while ensuring that messages are delivered with minimal delay.
Managing these connections is not just a matter of scaling servers horizontally. Each connection consumes memory and file descriptors, and the system must track connection state, including authentication and channel subscriptions. If a single server becomes overloaded, connection drops can cascade into reconnection storms, which amplify load and destabilize the system.
The challenge becomes more apparent when you consider fan-out delivery. A message sent to a channel with thousands of members must be delivered to all connected clients. Doing this naively by iterating over each connection would not scale, so the system relies on optimized fan-out strategies, often involving in-memory pub-sub mechanisms or distributed messaging layers.
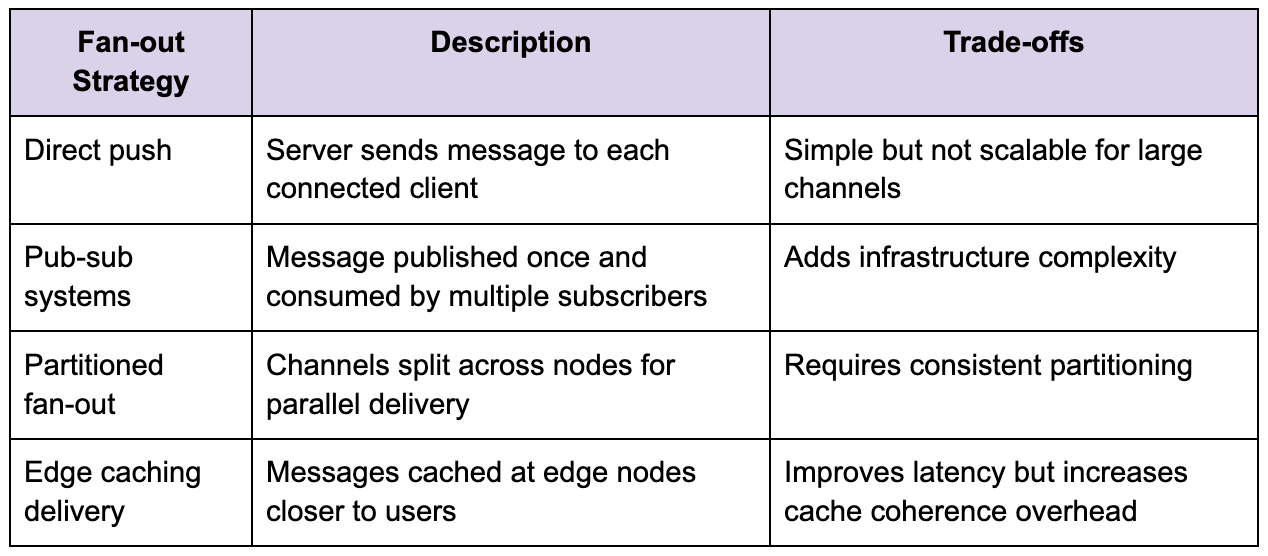
The choice of strategy depends heavily on observed traffic patterns. Designing for massive channels before they exist leads to the kind of premature optimization described earlier, where complexity is introduced without measurable benefit.
Message storage and consistency
While real-time delivery is what users notice, persistence is what makes Slack reliable. Messages must be stored durably so that users can retrieve history, search conversations, and recover from disconnections. This introduces a different set of constraints, particularly around write throughput and consistency.
Slack’s storage layer must handle a continuous stream of writes, often at very high volume, while ensuring that messages are stored in the correct order within each channel. Ordering is not trivial in a distributed system because messages may arrive at different nodes at slightly different times. Without a clear strategy, users could see messages out of order, which would degrade the user experience.
One common approach is to assign sequence numbers at the channel level, ensuring that each message has a definitive position. This requires coordination, which can become a bottleneck if not designed carefully. Another approach is to rely on timestamps combined with conflict resolution, but this introduces edge cases under high concurrency.
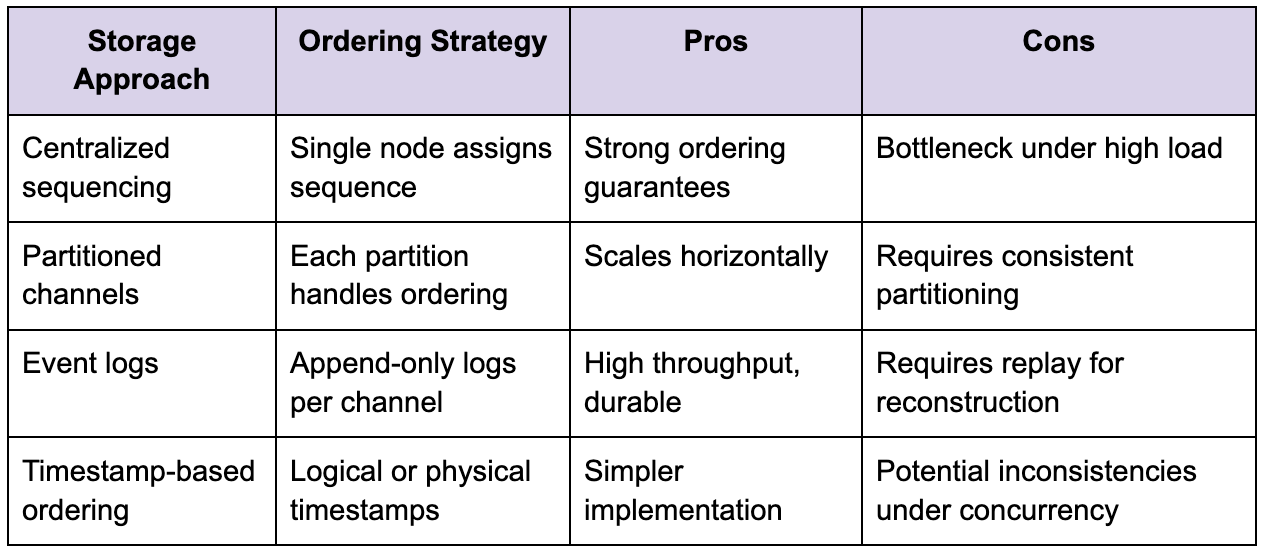
The trade-off between strict ordering and scalability is one of the defining tensions in Slack’s design. The system must maintain a consistent user experience while avoiding bottlenecks that limit throughput.
Handling failures and latency
As systems scale, failures become inevitable, and Slack is no exception. The design must account for partial failures, where some components are slow or unavailable while others continue to operate. This is where many real-time systems break down, especially when retry mechanisms amplify load instead of stabilizing the system.
The behavior described in your sample around cascading failures is particularly relevant here. A small increase in latency in a downstream component can lead to a buildup of in-flight requests, which in turn exhausts resources and propagates failures upstream. In Slack, this could manifest as delayed message delivery, dropped connections, or duplicate messages.
To mitigate this, the system must implement backpressure and rate limiting. Instead of allowing unlimited retries, the system should detect when a component is overloaded and reduce incoming traffic. Circuit breakers can prevent repeated attempts to communicate with failing services, while exponential backoff reduces the likelihood of retry storms.
Another important consideration is idempotency. If a message is retried due to a failure, the system must ensure that it is not stored or delivered multiple times. This requires unique identifiers and careful handling of duplicate requests.
Channel architecture and data partitioning
Slack’s channel-based model introduces natural boundaries for partitioning data, which can be leveraged to scale the system. Each channel can be treated as an independent unit for message storage and delivery, allowing the system to distribute load across multiple nodes.
However, partitioning is not without challenges. Users often belong to multiple channels, and cross-channel operations such as search or notifications require coordination across partitions. Additionally, hotspots can occur when certain channels become significantly more active than others, leading to uneven load distribution.
The system must therefore balance partitioning strategies with mechanisms for load redistribution. This may involve dynamically reassigning channels to different nodes or introducing additional layers of abstraction to manage data placement.
Observability and system behavior
One of the most critical aspects of designing a system like Slack is understanding its behavior under real traffic. Without proper observability, it is impossible to identify bottlenecks or predict how the system will respond to increased load.
Metrics such as latency percentiles, error rates, and resource utilization provide insight into system performance. In particular, tail latency is a key indicator of potential issues, as it reveals the outliers that can trigger cascading failures. This aligns closely with the emphasis in your sample on measuring P99 latency and saturation rather than relying on averages.
Logging and tracing are equally important, especially in distributed systems where requests span multiple components. Without consistent request identifiers and structured logs, diagnosing issues becomes a manual and error-prone process.
Evolving the architecture
The most important takeaway from Slack System Design is that architecture should evolve in response to real constraints rather than hypothetical scenarios. Starting with a simpler design allows teams to iterate and understand system behavior before introducing additional complexity.
As usage grows, the system can gradually introduce distribution, separating components that experience measurable pressure. This might involve extracting the message service to handle increased write load or scaling the WebSocket infrastructure to support more concurrent connections.
The key is to make these changes incrementally, validating each step with metrics and ensuring that new boundaries actually reduce bottlenecks rather than shifting them elsewhere. This mirrors the principle highlighted in your sample, where distribution is treated as a response to measured pressure rather than a default starting point.
Final perspective
Designing Slack is not about assembling a set of technologies. It is about understanding how real-time communication behaves under scale and how small inefficiencies can compound into systemic failures. The system must balance latency, consistency, and scalability while maintaining a user experience that feels instantaneous.
What makes Slack’s System Design interesting is not the components themselves, but the interactions between them. Every network hop, every retry, and every storage decision contributes to the overall behavior of the system. Without careful measurement and incremental evolution, complexity can quickly outpace understanding.
In practice, the most effective approach is the simplest one that works under current constraints. Build a system that is observable, predictable, and easy to reason about, and only introduce additional complexity when the data justifies it. That discipline is what separates systems that scale gracefully from those that collapse under their own design.