

What Grokking machine learning interview gets right about modern ML roles
Why machine learning interviews became more about reasoning, tradeoffs, and system thinking than memorizing algorithms

When machine learning interviews first started becoming mainstream across large tech companies, many engineers assumed the hardest part would be the mathematics. Candidates spent months reviewing linear algebra, probability theory, gradient descent, optimization formulas, and statistical concepts because they believed interview success depended primarily on remembering equations quickly under pressure. What many engineers eventually discovered, however, was that machine learning interviews evolved into something much broader than mathematical recall.
Companies increasingly wanted engineers who could reason about models, data quality, infrastructure constraints, experimentation tradeoffs, and production behavior simultaneously. That shift is one of the main reasons structured preparation approaches like Grokking Machine Learning Interview have become valuable for engineers transitioning into modern ML-focused roles.
Why machine learning interviews became harder than expected
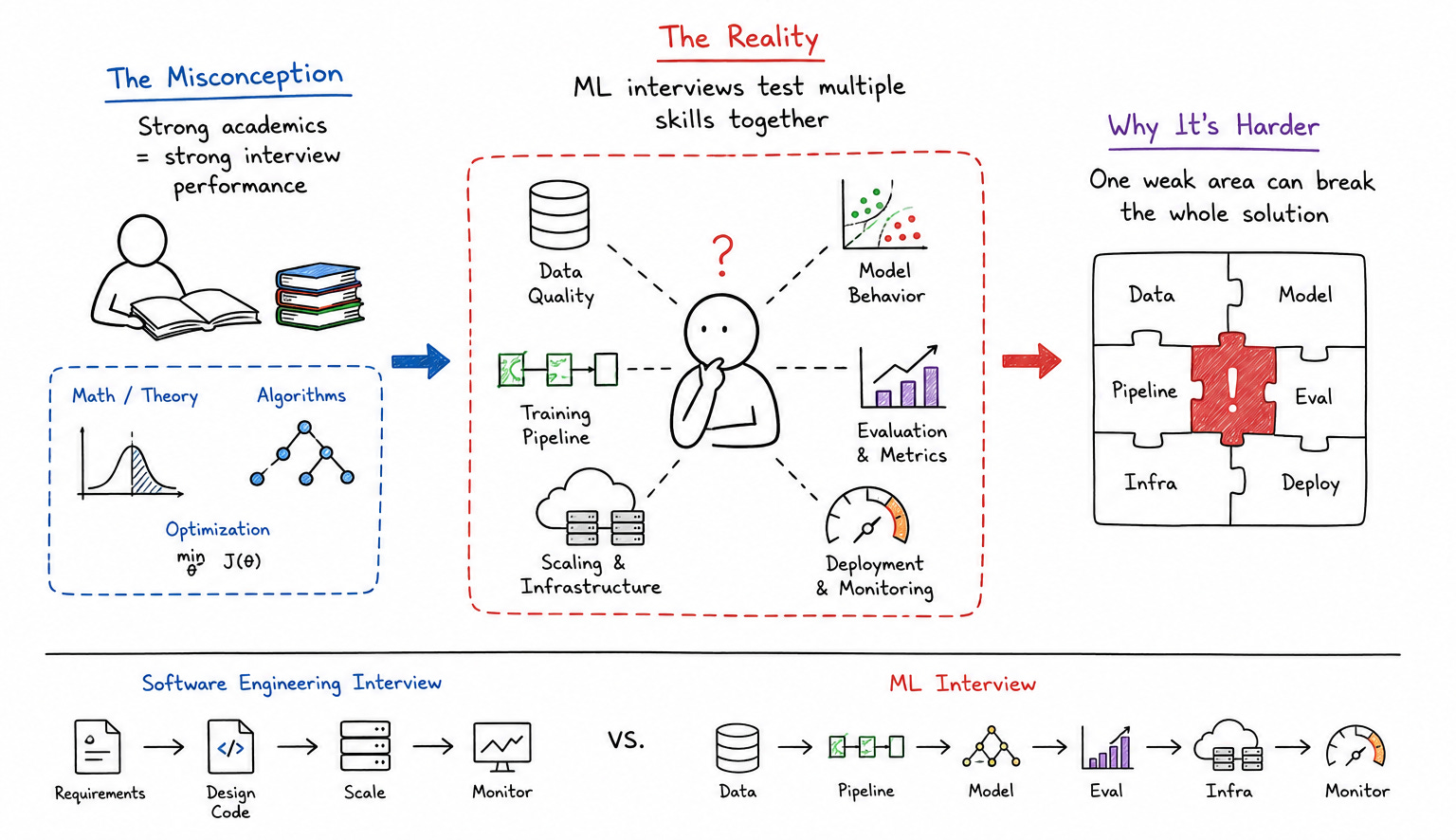
One of the biggest misconceptions about machine learning interview questions is the assumption that a strong academic understanding automatically translates into strong interview performance. In reality, many highly intelligent engineers struggle because machine learning interviews combine several different skill sets into a single conversation.
An engineer may understand supervised learning extremely well yet struggle when asked how a recommendation model behaves under skewed user traffic. Another candidate may know every optimization algorithm mathematically but fail to explain how training pipelines behave once datasets become noisy, imbalanced, or operationally inconsistent.
That complexity is what makes machine learning interviews fundamentally different from traditional software engineering interviews.
The shift from theory to practical reasoning
Earlier machine learning interviews often focused heavily on theory. Candidates solved mathematical derivations, explained gradient descent mechanics, or compared algorithms academically.
Modern interviews still evaluate fundamentals, but they increasingly prioritize practical reasoning.
Interviewers now ask questions like:
How would you detect model drift in production?
What happens when training data distribution changes over time?
How do you balance inference latency against model complexity?
How would you debug declining recommendation quality?
How would you deploy a model serving millions of requests per second?
These questions force candidates to think beyond textbook ML concepts because real-world machine learning systems operate under infrastructure, latency, and operational constraints continuously.
This is one reason structured preparation frameworks became important. Engineers needed a way to organize machine learning reasoning systematically instead of memorizing isolated concepts independently.
Why structured ML thinking matters more than memorization
One of the biggest problems engineers face during ML interview preparation is information overload.
Machine learning spans mathematics, statistics, data engineering, experimentation, distributed systems, feature pipelines, optimization, and infrastructure. Without structure, preparation quickly becomes chaotic because candidates jump randomly between topics without understanding how those topics connect operationally.
This often leads to a shallow understanding.
Candidates may memorize differences between random forests and gradient boosting but struggle to explain why one model behaves better under noisy datasets. Others may understand neural networks conceptually but fail to reason about overfitting, inference latency, or production deployment challenges.
Real machine learning systems are constrained systems
One of the most important shifts in modern ML preparation is understanding that machine learning systems are ultimately engineering systems.
A model does not operate in isolation. It depends on data pipelines, feature stores, serving infrastructure, observability systems, experimentation frameworks, and distributed compute resources.
That means every machine learning decision introduces tradeoffs.
Larger models may improve accuracy but increase inference latency. Aggressive feature engineering may improve predictions while complicating training consistency. Complex ensemble systems may increase performance while making debugging significantly harder.
Once engineers begin viewing machine learning through this systems perspective, interviews become far more manageable because the conversation shifts from memorization toward reasoning.
Why production ML systems fail differently
One thing many engineers underestimate during preparation is how fragile machine learning systems become once deployed into production environments.
Traditional backend systems usually fail visibly. APIs crash. Databases timeout. Infrastructure becomes unavailable.
Machine learning systems often fail silently.
Prediction quality gradually declines. Data distributions drift over time. Feedback loops amplify bias unintentionally. Feature pipelines become inconsistent. Models continue serving requests while producing increasingly poor outcomes underneath.
This operational complexity is one reason ML interviews increasingly focus on monitoring and production reliability.
The importance of data quality
One of the most common causes of ML system degradation is poor data quality.
A model trained on clean historical datasets may behave unpredictably once production data changes. Missing fields, inconsistent feature scaling, delayed events, corrupted labels, or skewed traffic patterns can gradually reduce model quality without triggering obvious infrastructure failures.
Strong machine learning engineers understand that model performance is deeply dependent on pipeline reliability.
This is why experienced interviewers often ask candidates how they would validate training data, detect feature inconsistencies, or monitor drift over time.
Candidates who think operationally usually perform much better because they recognize that machine learning infrastructure is fundamentally a data dependency system.
Why observability matters in ML systems
Another concept that changed modern machine learning engineering significantly is observability.
In ordinary software systems, observability focuses heavily on infrastructure metrics like latency, throughput, error rates, and resource utilization.
Machine learning systems require additional behavioral visibility.
Engineers need to monitor prediction distributions, feature drift, model confidence, training consistency, experiment performance, and long-term accuracy degradation simultaneously.
The following table highlights operational metrics commonly monitored in production ML environments.
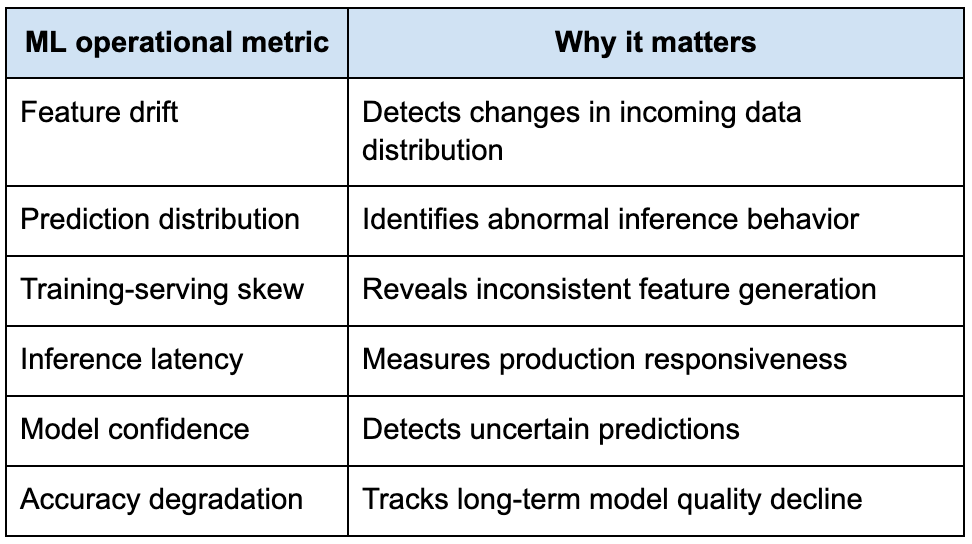
Once engineers begin thinking about machine learning systems operationally, their interview discussions become significantly more realistic.
Why ML interviews increasingly include System Design
One of the biggest changes in machine learning hiring over the past several years is the growing overlap between machine learning engineering and distributed systems engineering.
Earlier ML interviews often focused heavily on algorithms and mathematical concepts. Modern ML roles increasingly require understanding scalable infrastructure as well.
This shift happened because machine learning workloads became operationally demanding at scale.
Training pipelines process massive datasets across distributed clusters. Recommendation systems serve predictions under strict latency constraints. Search ranking systems require continuous experimentation. Real-time personalization systems depend on streaming infrastructure and online feature generation.
As a result, machine learning System Design interviews have become common, including discussions about scalability, reliability, deployment strategies, and infrastructure coordination.
The rise of end-to-end ML ownership
Another reason ML interviews evolved is that companies increasingly expect engineers to own larger portions of the machine learning lifecycle.
Earlier organizational structures separated responsibilities heavily. Data scientists focused on experimentation while infrastructure teams handled deployment independently.
Modern ML engineering roles increasingly blend those responsibilities together.
Engineers are often expected to understand:
Data ingestion pipelines
Training infrastructure
Model experimentation
Inference serving
Online feature systems
Observability pipelines
Deployment coordination
A/B testing infrastructure
Rollback strategies
This broader ownership model changed the nature of machine learning interviews because interviewers now evaluate systems thinking alongside modeling knowledge.
Why communication matters so much in ML interviews
A surprising number of machine learning interviews are not derailed by technical weakness, but by poor communication structure.
Machine learning systems involve many moving parts simultaneously. Candidates discussing datasets, models, feature pipelines, evaluation metrics, infrastructure constraints, experimentation, and deployment behavior can easily overwhelm the conversation if explanations become fragmented.
Strong ML interview answers usually evolve progressively.
The candidate first clarifies the business objective. Then they discuss data availability and constraints. Afterward, they explain modeling choices, evaluation metrics, deployment considerations, and operational monitoring gradually.
That layered communication style makes even highly technical discussions easier to follow.
Good ML interviews feel like collaborative debugging sessions
One thing that separates strong ML interviews from memorized responses is adaptability.
Interviewers often introduce changing constraints midway through the discussion. Dataset quality changes. Latency requirements become stricter. Traffic scales unexpectedly. Feedback loops emerge. Model performance degrades over time.
Strong candidates remain calm because they approach machine learning as an evolving engineering problem rather than a static mathematical exercise.
This adaptability matters enormously in production environments because machine learning systems continuously evolve alongside user behavior and data distributions.
Why feature engineering still matters
One of the interesting trends in modern machine learning is the tendency for engineers to focus heavily on model complexity while underestimating the importance of features.
Powerful architectures matter, but feature quality still determines a large portion of production model performance.
A relatively simple model trained on high-quality, well-structured features often outperforms a highly sophisticated model trained on noisy or inconsistent data.
This is one reason experienced interviewers still explore feature engineering discussions deeply.
Features shape model behavior
Features are not simply inputs. They shape how the model understands the underlying problem space.
For example, recommendation systems depend heavily on behavioral signals, temporal patterns, user preferences, and contextual interactions. Fraud detection systems rely on anomaly indicators, transaction relationships, and historical consistency. Ranking systems require relevance signals that evolve continuously over time.
Understanding how to design and validate those features becomes just as important as selecting the model itself.
Strong candidates usually recognize this naturally because they approach machine learning as a full pipeline rather than a single algorithm.
Why experimentation became central to ML engineering
Another major shift in machine learning engineering is the increasing importance of experimentation infrastructure.
Modern ML systems rarely rely on static deployments. Models evolve continuously through online evaluation, A/B testing, retraining workflows, and feedback-driven optimization.
This operational reality changed machine learning interviews significantly.
Interviewers now frequently explore experimentation strategy, rollout coordination, metric evaluation, and performance validation.
Offline metrics are not always enough
One of the hardest lessons many ML engineers learn is that strong offline evaluation metrics do not always translate into strong production outcomes.
A recommendation model may improve offline click-through predictions while reducing long-term user engagement. A ranking model may optimize short-term interactions while degrading content diversity. A fraud system may reduce false negatives while dramatically increasing operational review costs.
This is why production experimentation matters so much.
Strong ML engineers understand that machine learning optimization always exists within broader business and operational constraints.
Why machine learning interviews have become multidisciplinary
One reason machine learning interviews feel difficult today is that the role itself has become multidisciplinary.
Strong ML engineers now operate across statistics, software engineering, distributed systems, experimentation, infrastructure reliability, and product reasoning simultaneously.
That breadth can feel intimidating initially, especially for engineers transitioning from purely backend or purely research-oriented backgrounds.
Structured preparation approaches became valuable because they helped engineers organize these interconnected concepts into coherent reasoning frameworks.
The lasting impact of Grokking machine learning interview
One reason Grokking Machine Learning Interview became useful for many engineers is that it helped simplify a field that often feels fragmented during preparation.
Machine learning interviews are difficult not because the concepts are impossible to learn, but because they require combining multiple disciplines into a single structured conversation. Candidates must reason about data quality, modeling tradeoffs, infrastructure constraints, scalability behavior, monitoring systems, experimentation frameworks, and operational reliability simultaneously.
Providing engineers with a systematic way to approach those discussions made ML interviews significantly more approachable.
More importantly, it encouraged engineers to think about machine learning as a production engineering discipline rather than purely an academic subject.
That mindset ultimately matters far beyond interviews because modern machine learning systems succeed not only through model accuracy, but through reliability, scalability, maintainability, and operational clarity under real-world conditions.