

What you need to ace your Generative AI System Design interview
How to think through generative AI System Design problems with clarity, depth, and real production-level reasoning

If you walk into a generative AI System Design interview expecting it to behave like a traditional backend System Design round, you will quickly realize that the evaluation criteria are fundamentally different, because the system you are designing is not centered around data storage or API orchestration but around probabilistic generation powered by expensive and constrained compute.
What makes these interviews challenging is not just the breadth of topics, but the need to reason across two domains simultaneously, where distributed systems concerns such as scalability and reliability intersect with machine learning concerns such as model inference, tokenization, and latency-sensitive computation.
Most candidates struggle not because they lack knowledge of components, but because they fail to structure their thinking around the actual constraints that define generative AI systems. They often jump into describing vector databases, embeddings, or retrieval pipelines without first grounding the problem in the lifecycle of a single request, and that leads to answers that feel fragmented and overly tool-driven rather than system-driven.
The strongest candidates, in contrast, begin by asking what happens when a user submits a prompt and then build their design outward from that flow, ensuring that every component they introduce solves a clearly defined constraint rather than serving as a placeholder for completeness.
Starting with the request: What actually happens when a prompt arrives
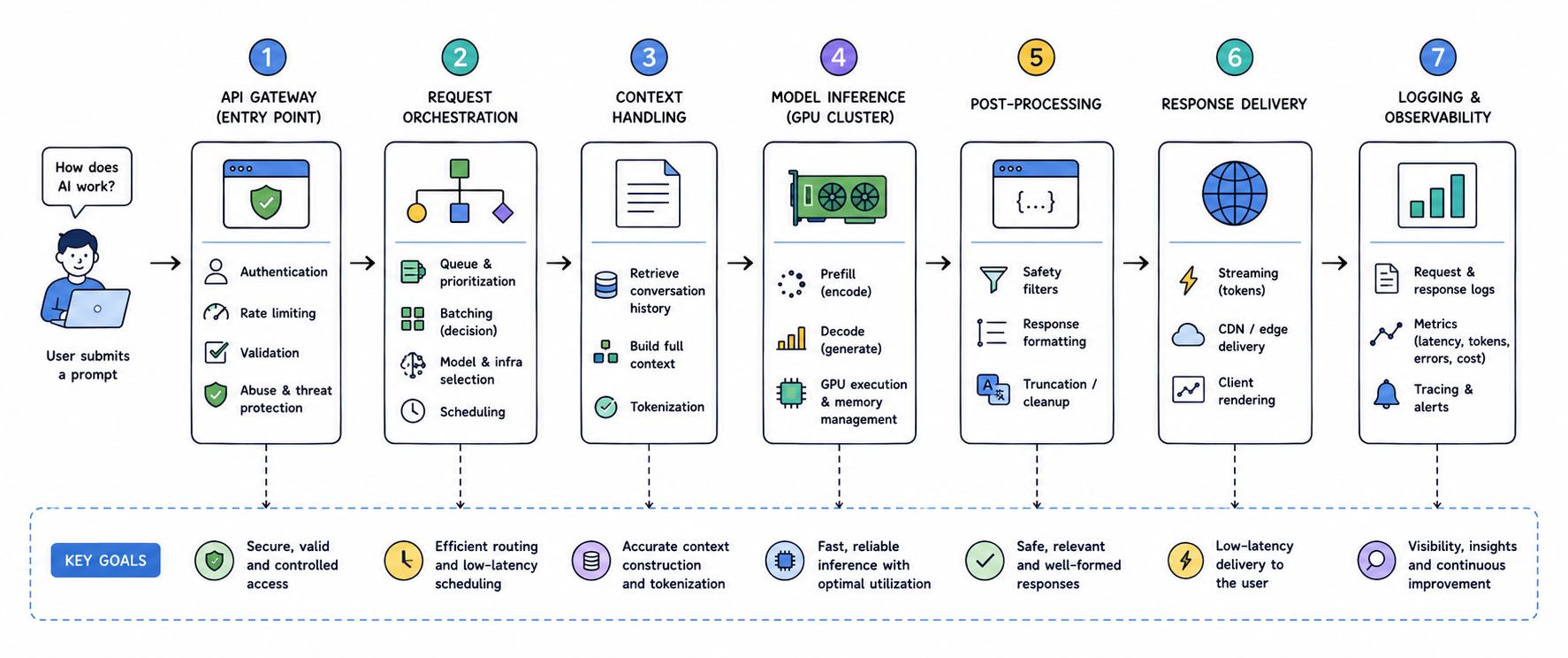
The most effective way to approach a generative AI System Design interview is to begin with the path of a single request, because that is where the real complexity lies. A user submits a prompt that might range from a short question to a long contextual instruction, and from that moment, the system must process the input, determine how it should be handled, and generate a response in a way that balances latency, cost, and quality.
At the entry point, the request is handled by an API gateway that performs authentication, rate limiting, and validation, but unlike traditional systems, where this layer is primarily concerned with correctness, here it plays a critical role in protecting downstream inference infrastructure. The system must prevent overload because generative AI workloads are compute-intensive, and allowing too many requests through at once can saturate GPU resources and degrade performance for all users.
Once the request is accepted, it is passed to a request orchestration layer that determines how the request will be processed, and this is where the design begins to diverge significantly from standard System Design patterns. The orchestrator must decide how to schedule the request, whether to batch it with others, and which model or infrastructure to use, all while considering the variability in request cost and the need to maintain low latency.
Core components in a generative AI system
To reason effectively during an interview, it helps to break the system into logical components, while still explaining how they interact in the request lifecycle rather than presenting them as isolated building blocks.
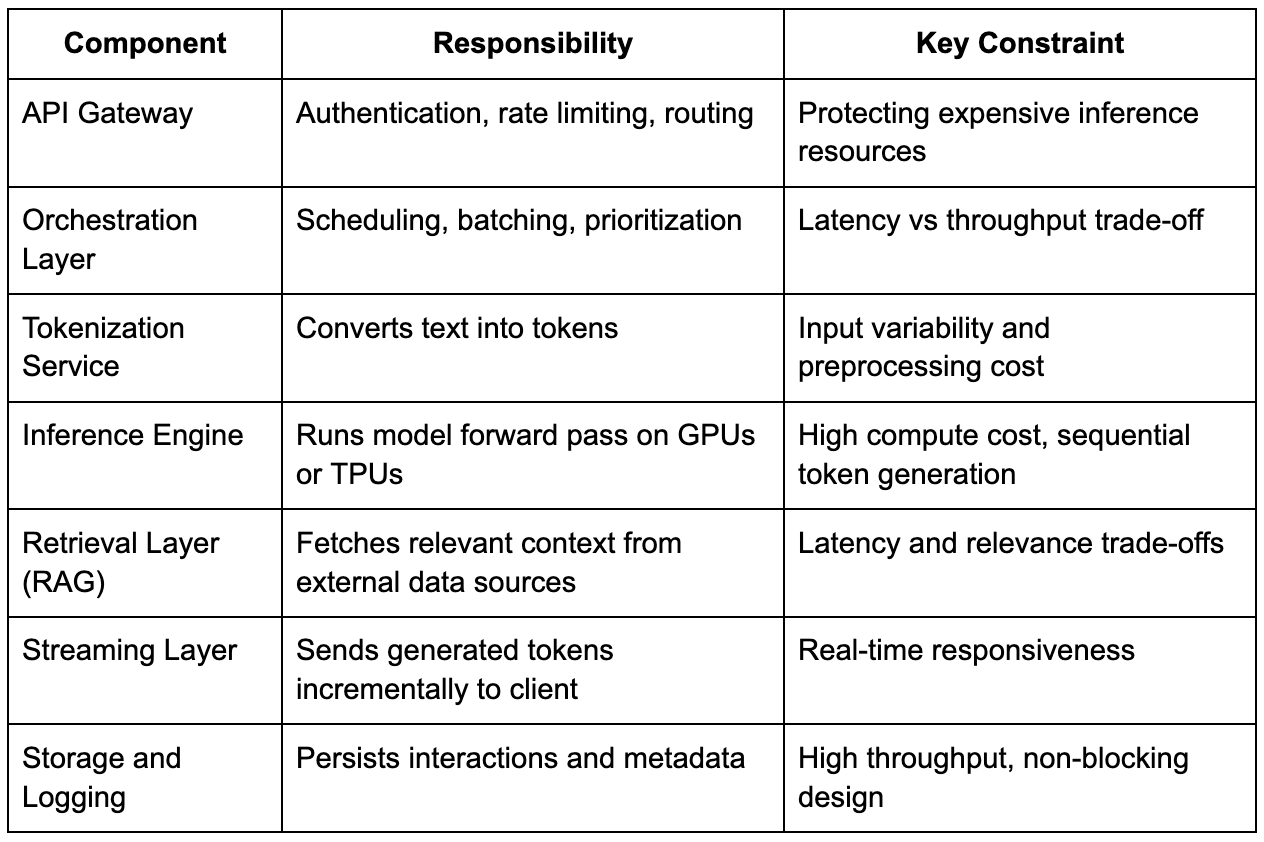
What matters in an interview is not just naming these components, but explaining why they exist and how they interact under load, because generative AI systems are defined by their constraints rather than their components.
Tokenization and why input size changes everything
One of the most overlooked aspects in generative AI System Design interviews is tokenization, even though it directly determines the computational cost of a request. Before a model can process input, the text must be converted into tokens, and the length of this token sequence has a significant impact on performance, because transformer models scale poorly with longer sequences due to attention mechanisms.
This introduces variability that does not exist in most backend systems, where requests are relatively uniform in cost. In generative AI systems, a short query might require minimal compute, while a long prompt with extensive context can be orders of magnitude more expensive, and the system must account for this variability when scheduling requests.
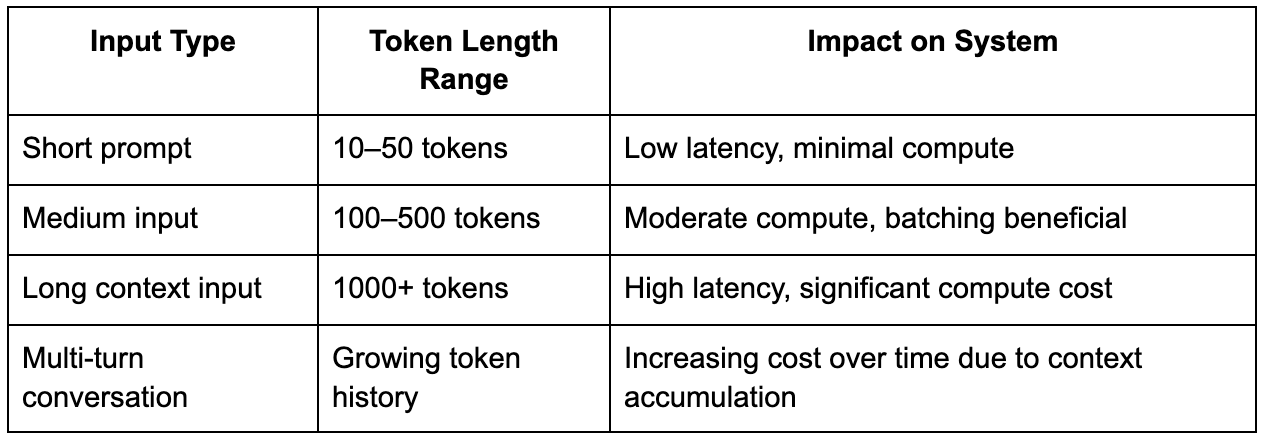
Strong candidates explicitly mention this variability and explain how it influences design decisions, particularly around batching, scheduling, and cost control.
Inference: The real bottleneck in the system
The inference layer is where generative AI systems fundamentally differ from traditional systems, because instead of executing deterministic logic, the system performs a forward pass through a neural network with billions of parameters, and this process must be repeated for each generated token. This introduces a sequential dependency that limits parallelism, since each token depends on the previously generated tokens.
In an interview setting, it is important to articulate why this matters because it directly impacts scalability. You cannot simply scale horizontally in the same way you would for stateless services, because the bottleneck is not just request volume but compute per request. This is why GPUs or TPUs are used, and why efficient utilization of these resources becomes a central concern in System Design.
Batching is one of the primary techniques used to improve efficiency, allowing multiple requests to share compute resources, but it introduces a trade-off between throughput and latency. Waiting too long to batch requests can increase response times, while batching too aggressively can reduce responsiveness, and the system must balance these competing goals dynamically.
Retrieval-augmented generation and external data integration
In many generative AI interview problems, particularly those involving domain-specific knowledge, candidates are expected to incorporate retrieval-augmented generation, which allows the system to fetch relevant information from external data sources and include it in the prompt before generating a response.
This introduces an additional layer of complexity because the system must perform retrieval quickly enough to avoid adding significant latency, while also ensuring that the retrieved information is relevant and improves the quality of the response. The retrieval layer often involves vector databases, embedding generation, and similarity search, but simply mentioning these components is not sufficient.
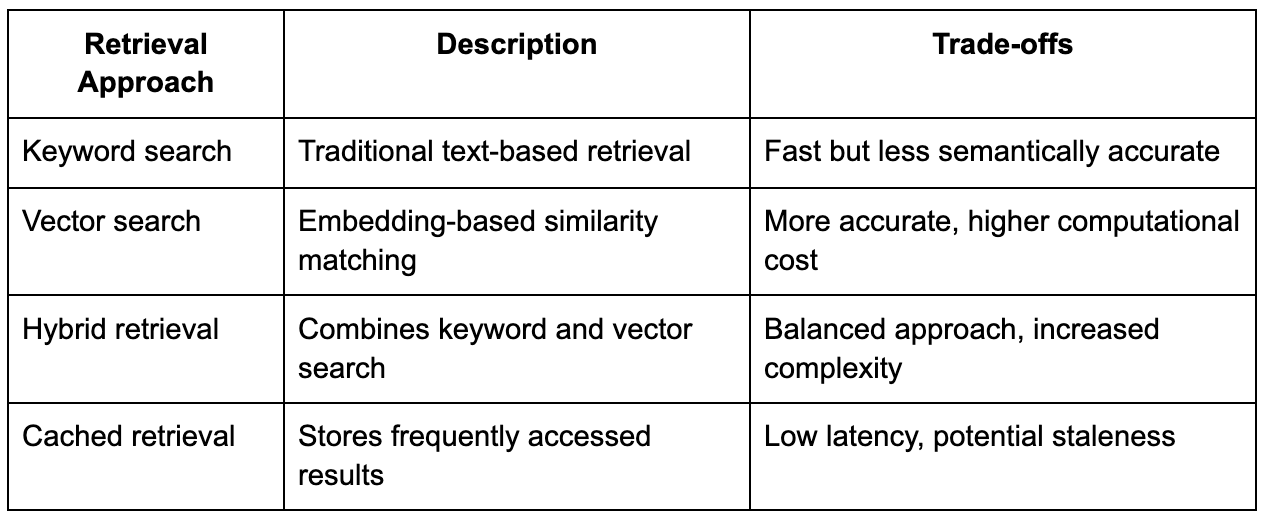
What interviewers are looking for is an understanding of how retrieval affects latency, consistency, and system complexity, and how it integrates with the overall request flow.
Streaming responses and user experience
One of the defining characteristics of generative AI systems is that responses are often streamed token by token, rather than being returned all at once, and this has a significant impact on user experience. Streaming reduces perceived latency, making the system feel more responsive, even though the total computation time remains unchanged.
However, streaming introduces challenges in terms of connection management and backpressure handling, because the system must maintain open connections and ensure that tokens are delivered smoothly without overwhelming the client. In an interview, discussing these challenges demonstrates a deeper understanding of how user experience is shaped by System Design decisions.
Handling failures and variability in production
Failures in generative AI systems are more complex than in traditional systems, because partial responses may already have been generated and sent to the user, making retries less straightforward. Additionally, the cost of reprocessing a request is high, so the system must minimize failures before they reach the inference stage.
Another important consideration is variability in request cost, which can lead to resource contention if not managed properly. Large requests can monopolize GPU resources, causing delays for other users, and the system must implement strategies such as prioritization, token limits, and load shedding to maintain stability.
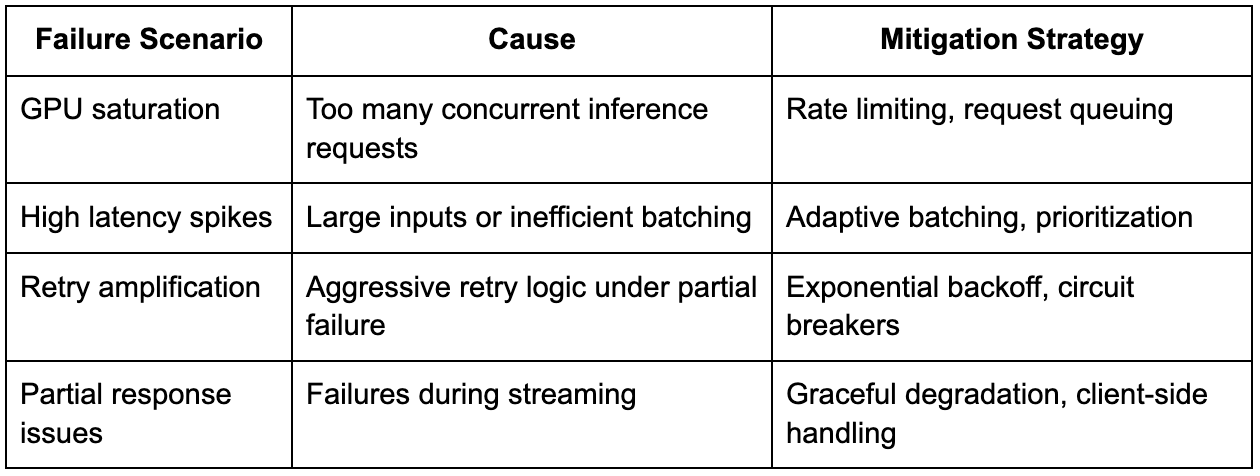
Explaining these scenarios in an interview setting shows that you understand not just how the system works under ideal conditions, but how it behaves under stress.
Observability and performance monitoring
A generative AI system cannot be effectively managed without strong observability, because the interaction between components is complex and often non-linear. Metrics such as latency percentiles, GPU utilization, request queue lengths, and error rates provide insight into system performance and help identify bottlenecks.
Tail latency is particularly important because it reflects the worst-case performance that can impact user experience. Without monitoring P95 or P99 latency, it becomes difficult to detect issues that may not be visible in average metrics but still affect a significant portion of users.
Tracing is also critical, especially in systems that involve multiple layers of orchestration, retrieval, and inference, because it allows engineers to follow requests through the system and understand how different components interact.
How to structure your answer in the interview
What separates strong candidates from average ones is not the number of components they mention, but the clarity and coherence of their reasoning. A strong answer begins with the request lifecycle, identifies key constraints such as latency and compute cost, and introduces components only when they are needed to address those constraints.
Instead of listing technologies, focus on explaining trade-offs, such as why batching is necessary but introduces latency, or why retrieval improves accuracy but adds complexity. This approach demonstrates that you are thinking in terms of system behavior rather than implementation details.
Final perspective
Generative AI System Design interviews are about demonstrating that you can reason through a system defined by high computational cost, variability, and real-time constraints. The system must balance efficiency, scalability, and user experience, and every design decision reflects a trade-off between these factors.
What makes these interviews challenging is that they require a deeper level of understanding, where you must connect concepts from distributed systems and machine learning into a cohesive narrative. Without that connection, answers tend to feel either too abstract or too fragmented.
In practice, the most effective approach is to stay grounded in the request lifecycle, focus on constraints, and evolve the design incrementally, ensuring that every component you introduce serves a clear purpose. That discipline not only leads to better interview performance, but also reflects how real-world generative AI systems are actually designed and scaled.