

What you need to know before your Meta ML System Design interview
A practical engineering guide to machine learning System Design interviews at Meta

The Meta ML System Design interview feels difficult for a reason because it sits at the intersection of distributed systems engineering, machine learning infrastructure, large-scale data processing, and product behavior under extreme scale.
Many candidates prepare for these interviews by studying machine learning models in isolation or memorizing System Design templates independently, only to realize during the interview that Meta expects you to reason about both worlds simultaneously. The conversation is rarely about implementing a neural network from scratch or drawing a generic microservices diagram.
Instead, the interview becomes an engineering discussion about how machine learning systems behave operationally when billions of users continuously generate behavioral data that must be ingested, processed, ranked, served, monitored, and retrained across distributed infrastructure. The hardest part is not knowing machine learning terminology. The hardest part is understanding how ML systems evolve once they operate under real production workloads.
Why the Meta ML System Design interview feels different
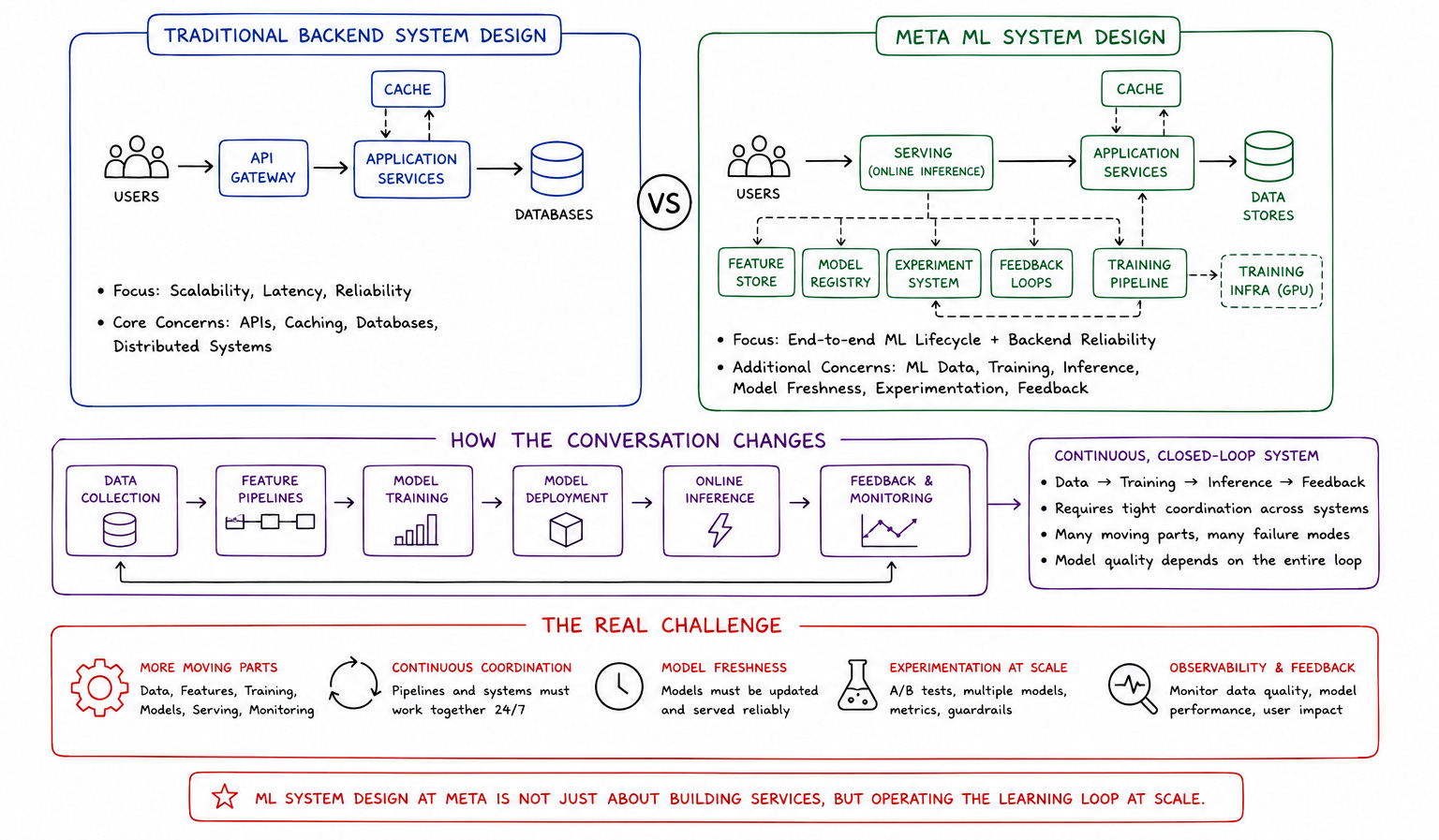
Traditional backend System Design interviews primarily evaluate scalability, APIs, caching, databases, and distributed infrastructure behavior. Machine learning System Design interviews at Meta introduce another layer of complexity because the architecture must continuously coordinate both data systems and learning systems simultaneously.
This changes the conversation completely.
A normal backend service may focus primarily on latency and reliability. An ML-powered platform must additionally manage feature pipelines, training infrastructure, online inference, model freshness, experimentation systems, and feedback loops continuously.
That operational coordination becomes the real challenge.
ML systems are continuously evolving systems
One of the most important mindset shifts in Meta machine learning interviews is understanding that machine learning systems are never static.
Traditional software systems usually execute deterministic business logic. ML systems continuously evolve based on incoming behavioral data.
The recommendation model serving users today may already be partially outdated tomorrow because user behavior changes continuously. Trends shift. Content evolves. Engagement patterns fluctuate. Distribution drift appears gradually over time.
This means ML infrastructure is fundamentally built around continuous adaptation.
Strong candidates recognize this early instead of discussing machine learning models as isolated prediction engines, helping them crack the machine learning System Design interview.
The infrastructure matters as much as the model
Another misconception candidates frequently have is assuming the interviewer primarily cares about model architecture.
In reality, Meta ML interviews often focus more heavily on operational ML infrastructure than on theoretical modeling details.
A highly sophisticated ranking model becomes operationally useless if inference latency exceeds user-facing constraints, if feature pipelines become inconsistent, or if training infrastructure cannot scale reliably.
The System Design discussion becomes deeply infrastructure-oriented.
What Meta interviewers are actually evaluating
Many candidates enter these interviews expecting algorithmic machine learning questions, but Meta ML System Design interviews usually evaluate engineering judgment under scale rather than pure ML theory.
The interviewer wants to understand whether you can design systems that successfully operationalize machine learning in production.
Core evaluation areas
The table below reflects several dimensions commonly evaluated during Meta ML System Design interviews.
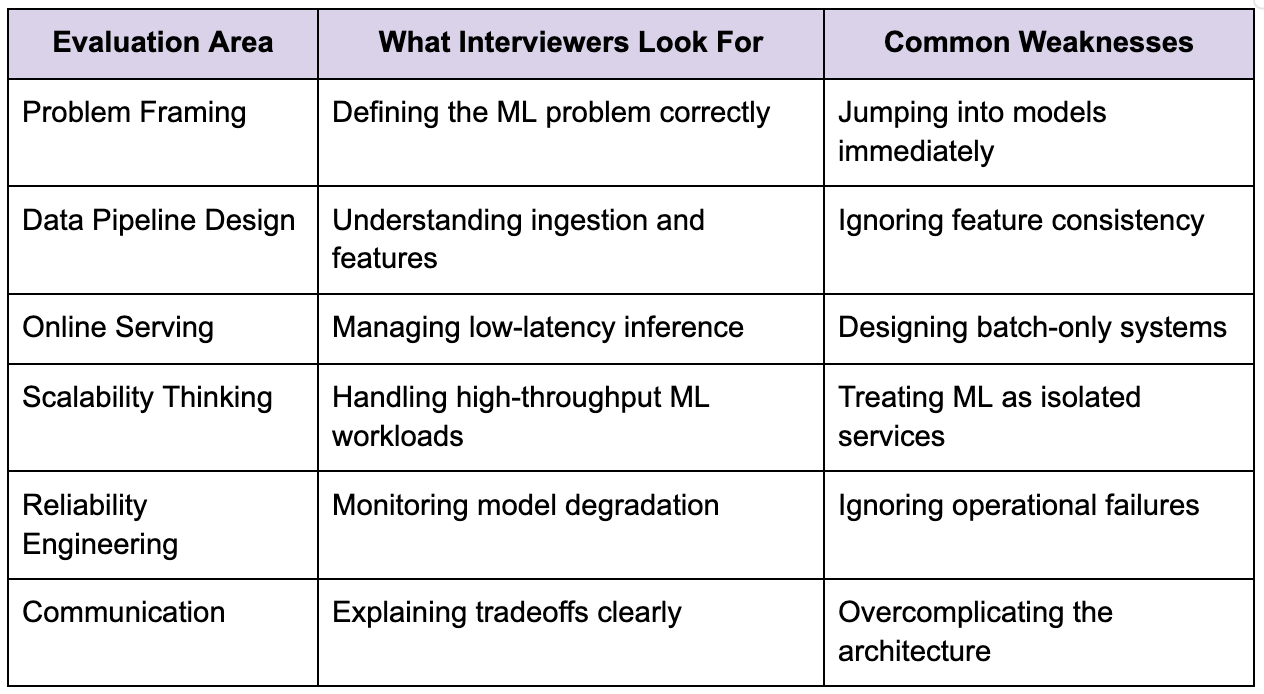
Strong candidates consistently explain why specific ML infrastructure decisions exist rather than only naming technologies or models.
For example, instead of casually mentioning embeddings or transformers, they explain how those systems affect latency, feature retrieval complexity, serving costs, and retraining workflows.
That operational reasoning matters enormously.
Start with the product problem first
One of the biggest mistakes candidates make is jumping directly into machine learning architecture before understanding the actual product goal.
Suppose the interviewer asks you to design an ML-powered recommendation system similar to Instagram Reels or Facebook Feed.
The wrong approach immediately starts discussing deep learning models and feature stores without clarifying the business behavior first.
A stronger approach begins with requirements.
Clarifying the objective function
The first step is understanding what the system is optimizing for.
Are we optimizing watch time? Click-through rate? Long-term engagement? Session duration? Retention? Diversity? Content quality?
This matters because the optimization target fundamentally shapes the architecture.
A system optimized purely for clicks behaves differently from one optimized for long-term user retention.
Defining product constraints
Strong candidates also clarify operational assumptions early.
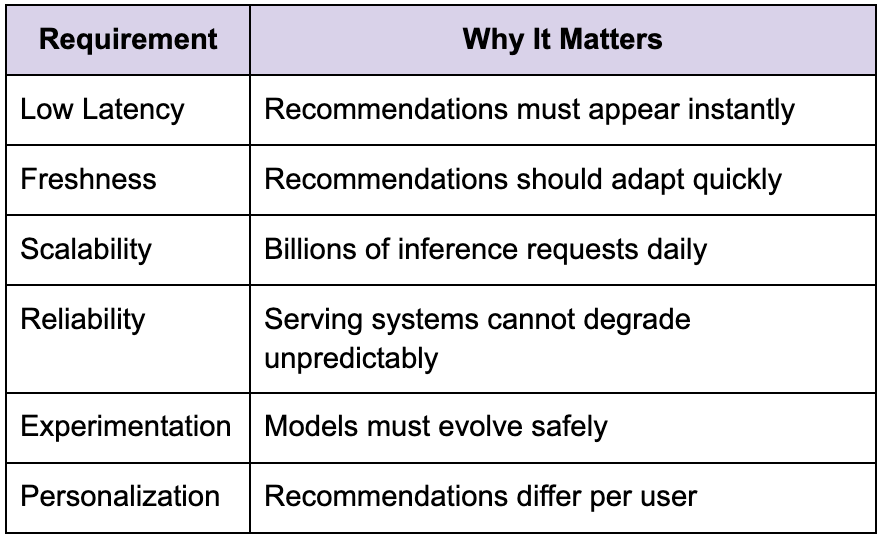
These constraints determine nearly every architectural decision afterward.
Designing the data ingestion pipeline
The data pipeline becomes the foundation of the entire ML system because recommendation quality depends heavily on behavioral signals flowing through the infrastructure continuously.
At the Meta scale, user interactions generate enormous streams of events every second.
User behavior generates the training data
Every interaction becomes a signal.
Likes, comments, shares, follows, watch duration, scroll behavior, pauses, clicks, reactions, and session activity continuously feed machine learning pipelines.
This creates a streaming systems problem more than a traditional database problem.
The platform must ingest, process, aggregate, and distribute these events continuously across the distributed infrastructure.
Streaming architectures become essential
Large-scale ML systems rely heavily on streaming pipelines.
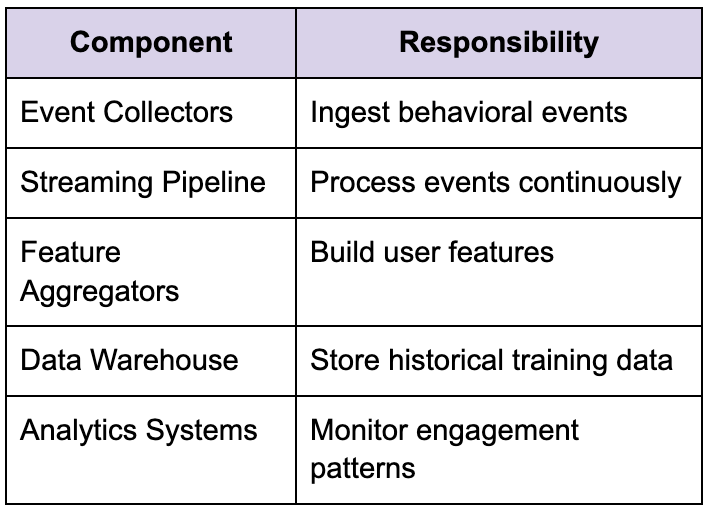
Strong candidates explain why streaming systems matter operationally.
Recommendation freshness depends heavily on how quickly user interactions propagate into downstream feature systems. Delayed pipelines produce stale recommendations very quickly.
Feature engineering becomes an infrastructure problem
One of the most underestimated aspects of ML System Design interviews is feature infrastructure.
Many candidates focus heavily on the model itself while ignoring how features are generated, stored, synchronized, and served consistently.
At the production scale, feature systems often become more operationally complex than the models themselves.
Offline and online features behave differently
ML systems usually rely on two major categories of features.
Offline features
These are generated through large-scale batch processing pipelines using historical datasets.
Examples include long-term engagement patterns, topic preferences, or embedding generation.
Online features
These update continuously updated based on real-time user interactions.
Examples include recent watch activity, session context, or trending interests.
The challenge becomes consistency.
If training pipelines use one version of features while inference pipelines use different feature calculations, model quality degrades significantly.
This issue is commonly known as training-serving skew.
Feature stores solve coordination problems
Modern ML systems rely heavily on feature stores.
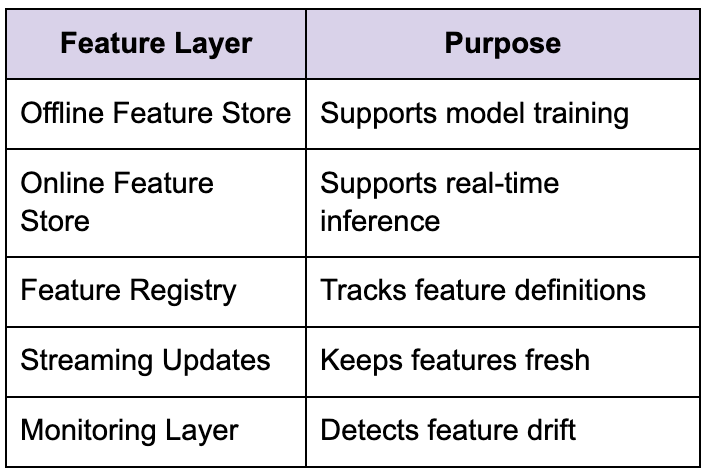
Strong candidates explain feature infrastructure operationally rather than only conceptually.
Recommendation systems become multi-stage pipelines
Most large-scale Meta recommendation systems rely on multi-stage architectures because evaluating every content object for every user becomes computationally impossible.
The system narrows the problem progressively.
Candidate generation
The first stage retrieves potentially relevant content from enormous datasets.
This stage often relies on embeddings, collaborative filtering, graph relationships, or behavioral similarity systems to narrow the search space quickly.
Ranking systems
The ranking stage scores candidate content using machine learning models.
This layer evaluates engagement likelihood, relevance, freshness, diversity, and user preferences simultaneously.
Re-ranking and filtering
The final stage applies policy constraints, diversity adjustments, safety checks, and ranking refinements before generating the final feed.
The architecture below reflects how recommendation systems separate operational responsibilities.
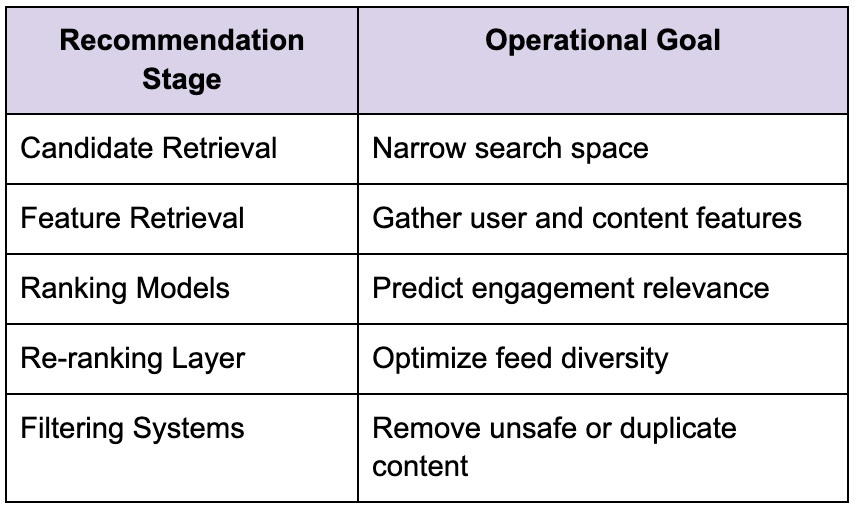
Strong candidates explain why this staged architecture exists operationally rather than merely describing it academically.
Online inference becomes the latency bottleneck
One of the hardest parts of large-scale ML systems is online serving.
A recommendation model may achieve excellent offline accuracy while remaining unusable operationally because inference latency becomes too expensive at scale.
Inference systems must stay fast
Meta-scale recommendation systems serve enormous numbers of predictions continuously.
Even small increases in inference latency compound dramatically at high throughput.
This means serving systems prioritize efficiency aggressively.
Tradeoffs between complexity and latency
Larger models often improve prediction quality while increasing serving cost and latency simultaneously.
Strong candidates recognize this tradeoff directly.
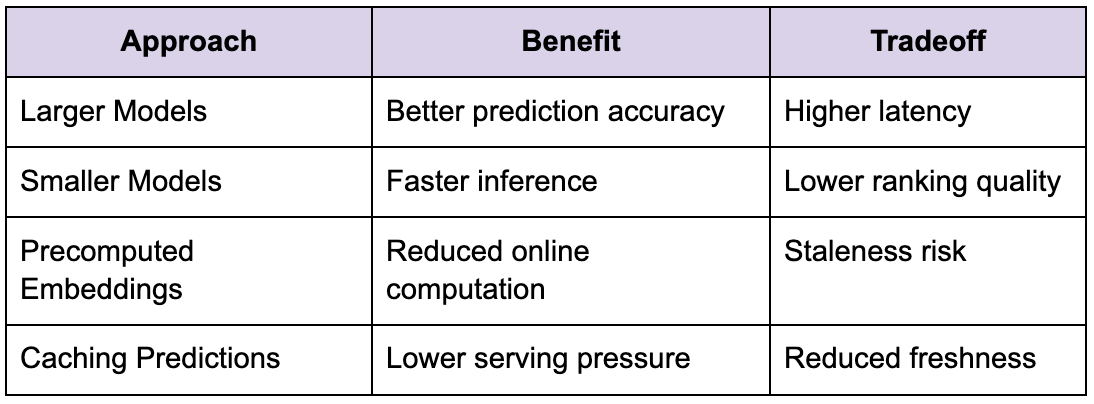
This operational balancing act becomes central to many Meta ML discussions.
Training pipelines evolve continuously
Machine learning systems are not deployed once and forgotten.
The training infrastructure continuously re-trains models using updated behavioral data.
Retraining becomes operationally necessary
User behavior evolves constantly.
Recommendation models trained on last month’s engagement patterns may already be outdated today.
This means retraining pipelines become continuous production workflows.
Offline training infrastructure
Large-scale training systems usually rely on a distributed computing infrastructure capable of processing enormous datasets efficiently.
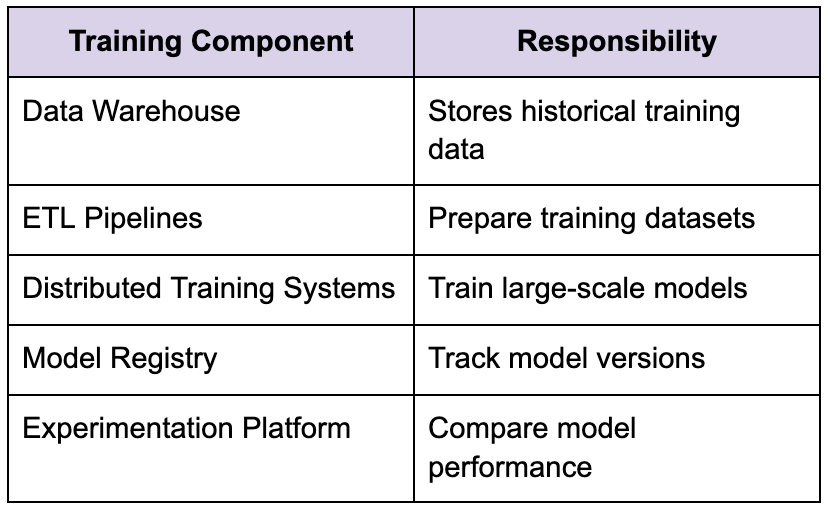
Strong candidates explain how retraining workflows integrate with serving systems safely rather than discussing training in isolation.
Experimentation infrastructure becomes critical
One of the defining characteristics of Meta engineering culture is experimentation.
Large-scale ML systems continuously test ranking changes, feature updates, and model improvements through controlled experiments.
A/B testing drives model evolution
Recommendation systems rarely deploy globally immediately.
Instead, new models are evaluated gradually through experimentation frameworks measuring engagement metrics, retention behavior, and latency impact.
This introduces additional operational complexity.
The platform must support traffic splitting, experiment isolation, metrics collection, and rollback strategies safely.
Safe rollout strategies matter
Strong candidates proactively discuss rollout safety.
Suppose a new ranking model increases click-through rates but unexpectedly harms long-term retention. How quickly can the system detect the regression and revert safely?
These operational discussions often reveal real production engineering maturity.
Reliability engineering becomes the real challenge
Average candidates explain how ML systems function normally.
Strong candidates explain how they fail.
Distributed ML systems fail constantly in subtle ways.
Feature pipelines lag behind ingestion traffic. Recommendation systems serve stale embeddings. Training jobs fail partially. Inference latency spikes during traffic surges. Data drift silently degrades model quality.
Strong candidates proactively discuss these realities.
Graceful degradation matters
Suppose the ranking system becomes temporarily unavailable during peak traffic.
What happens next?
Does the platform fall back to cached recommendations? Are simpler heuristic rankings used temporarily? Does feed quality degrade gracefully instead of failing completely?
These operational questions matter enormously because production ML systems are constrained less by ideal-case accuracy and more by reliability under scale.
Observability becomes essential
ML systems introduce an entirely new category of operational observability problems.
Traditional backend monitoring focuses heavily on latency, throughput, and infrastructure health. ML systems additionally require model-level monitoring.
Infrastructure monitoring is not enough
A serving system may remain technically healthy while recommendation quality silently degrades due to feature drift or stale models.
This means ML observability must track both system metrics and model behavior simultaneously.
ML observability infrastructure
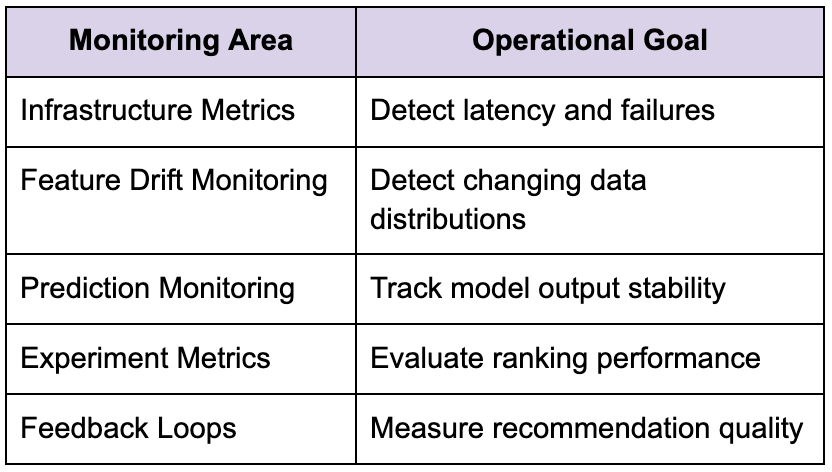
Strong candidates understand that ML systems require operational visibility beyond ordinary distributed systems monitoring.
How senior engineers approach Meta ML interviews differently
One noticeable difference between senior candidates and less experienced engineers is that senior engineers think continuously about operational coordination rather than only model architecture.
Junior candidates often focus heavily on ML algorithms. Senior engineers focus more on data freshness, feature consistency, rollout safety, scalability, and observability.
This distinction matters enormously because production ML systems are infrastructure systems first and modeling systems second.
Senior engineers think operationally
For example, a senior engineer discussing recommendation infrastructure may explain how stale feature propagation affects ranking quality or how embedding refresh intervals influence personalization freshness.
Those operational insights reveal real production experience.
Senior candidates also avoid unnecessary complexity early in the discussion. Instead of immediately proposing massive distributed ML stacks, they begin with simpler scalable systems and evolve complexity gradually according to measurable bottlenecks.
That progression mirrors how successful ML systems mature operationally.
The real goal of the Meta ML System Design interview
At its core, the Meta ML System Design interview is not testing whether you can memorize machine learning terminology or reproduce a perfect recommendation architecture from memory.
It is evaluating whether you can think like an engineer responsible for production ML systems operating under enormous scale, continuous feedback loops, low-latency serving constraints, and evolving user behavior.
The strongest candidates are rarely the engineers who mention the most advanced models. They are usually the engineers who stay grounded in operational behavior, explain tradeoffs clearly, and understand how ML systems behave under real production pressure.
That mindset changes how you prepare entirely.
Instead of memorizing architecture diagrams or ML buzzwords, focus on understanding why large-scale ML systems evolve the way they do. Learn how feature pipelines coordinate, how recommendation systems process feedback loops, how inference latency affects architecture decisions, how experimentation frameworks guide model rollout, and how observability exposes hidden degradation problems.
Once you begin thinking about ML systems through operational behavior instead of surface-level diagrams, the Meta ML System Design interview starts feeling less like a theoretical exam and more like the kind of engineering discussion experienced ML infrastructure teams have every day.